The right way to Automate Search engine optimization Key phrase Clustering by way of Seek Intent with Python-Search engine optimization Ebook

Editor’s be aware: As 2021 winds down, we’re celebrating with a 12 Days of Christmas Countdown of the preferred, useful professional articles on Seek Engine Magazine this 12 months.
This assortment used to be curated by way of our editorial crew in response to every article’s efficiency, application, high quality, and the worth created for you, our readers.
On a daily basis till December twenty fourth, we’ll repost probably the most best possible columns of the 12 months, beginning at No. 12 and counting all the way down to No. 1. Nowadays is quantity 11, at first revealed on July 28, 2021.
Andreas Voniatis did an incredible task explaining the best way to create key phrase clusters by way of seek intent the usage of Python. The pictures and screencaps make it simple to apply alongside, step-by-step, so even probably the most newbie Python person can apply alongside. Neatly performed, Andreas!
Commercial
Proceed Studying Under
Thanks for contributing to Seek Engine Magazine and sharing your knowledge with readers.
Revel in everybody!
There’s so much to find out about seek intent, from the usage of deep studying to deduce seek intent by way of classifying textual content and breaking down SERP titles the usage of Herbal Language Processing (NLP) ways, to clustering in response to semantic relevance with the advantages defined.
Now not most effective do we all know the advantages of interpreting seek intent – we’ve got plenty of ways at our disposal for scale and automation, too.
However frequently, the ones contain construction your personal AI. What if you happen to don’t have the time nor the data for that?
Commercial
Proceed Studying Under
On this column, you’ll be told a step by step procedure for automating key phrase clustering by way of seek intent the usage of Python.
SERPs Comprise Insights For Seek Intent
Some strategies require that you just get all the replica from titles of the score content material for a given key phrase, then feed it right into a neural community style (which it’s a must to then construct and check), or perhaps you’re the usage of NLP to cluster key phrases.
There may be some other means that allows you to use Google’s very personal AI to do the be just right for you, with no need to scrape all of the SERPs content material and construct an AI style.
Let’s think that Google ranks web site URLs by way of the chance of the content material pleasurable the person question in descending order. It follows that if the intent for 2 key phrases is similar, then the SERPs usually are equivalent.
For years, many Search engine optimization pros when compared SERP effects for key phrases to deduce shared (or shared) seek intent to stick on best of Core Updates, so that is not anything new.
The worth-add this is the automation and scaling of this comparability, providing each pace and larger precision.
How To Cluster Key phrases By way of Seek Intent At Scale The usage of Python (With Code)
Start together with your SERPs ends up in a CSV obtain.
Commercial
Proceed Studying Under
1. Import The Record Into Your Python Pocket book.
import pandas as pd
import numpy as np
serps_input = pd.read_csv('knowledge/sej_serps_input.csv')
serps_input
Under is the SERPs record now imported right into a Pandas dataframe.
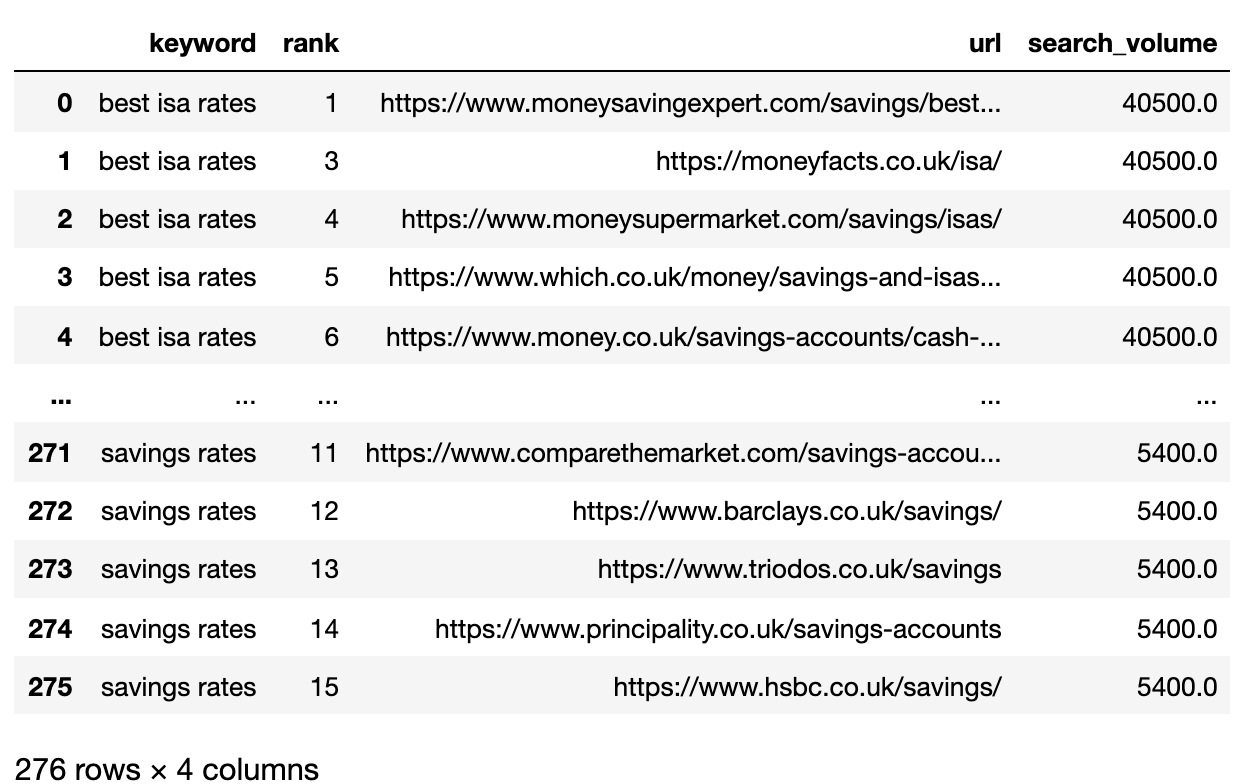
2. Filter out Information For Web page 1
We need to evaluate the Web page 1 result of every SERP between key phrases.
Commercial
Proceed Studying Under
We’ll break up the dataframe into mini key phrase dataframes to run the filtering serve as sooner than recombining right into a unmarried dataframe, as a result of we need to filter out at key phrase degree:
# Break up
serps_grpby_keyword = serps_input.groupby("key phrase")
k_urls = 15
# Follow Mix
def filter_k_urls(group_df):
filtered_df = group_df.loc[group_df['url'].notnull()]
filtered_df = filtered_df.loc[filtered_df['rank'] <= k_urls]
go back filtered_df
filtered_serps = serps_grpby_keyword.follow(filter_k_urls)
# Mix
## Upload prefix to column names
#normed = normed.add_prefix('normed_')
# Concatenate with preliminary knowledge body
filtered_serps_df = pd.concat([filtered_serps],axis=0)
del filtered_serps_df['keyword']
filtered_serps_df = filtered_serps_df.reset_index()
del filtered_serps_df['level_1']
filtered_serps_df
3. Convert Rating URLs To A String
As a result of there are extra SERP consequence URLs than key phrases, we wish to compress the ones URLs right into a unmarried line to constitute the key phrase’s SERP.
Right here’s how:
# convert effects to strings the usage of Break up Follow Mix
filtserps_grpby_keyword = filtered_serps_df.groupby("key phrase")
def string_serps(df):
df['serp_string'] = ''.sign up for(df['url'])
go back df
# Mix
strung_serps = filtserps_grpby_keyword.follow(string_serps)
# Concatenate with preliminary knowledge body and blank
strung_serps = pd.concat([strung_serps],axis=0)
strung_serps = strung_serps[['keyword', 'serp_string']]#.head(30)
strung_serps = strung_serps.drop_duplicates()
strung_serps
Under displays the SERP compressed right into a unmarried line for every key phrase.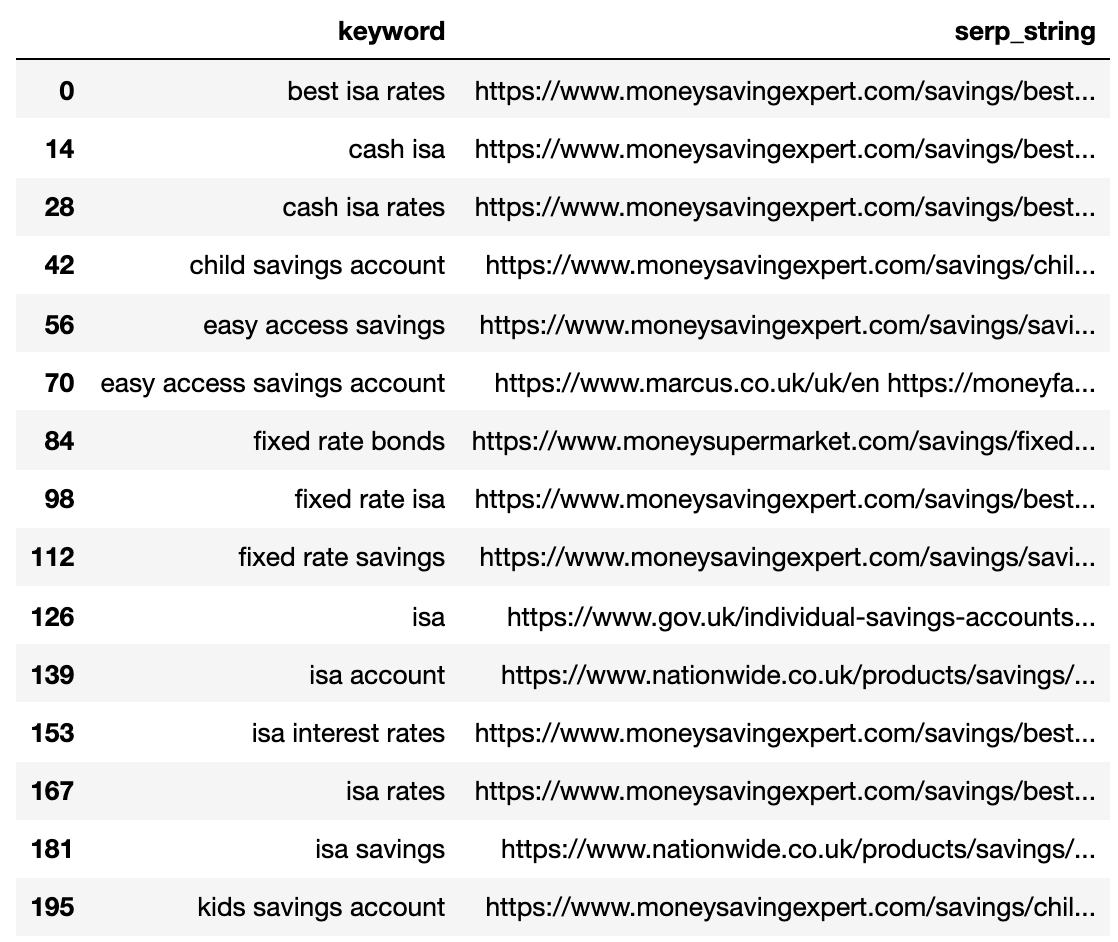
4. Evaluate SERP Similarity
To accomplish the comparability, we now want each and every aggregate of key phrase SERP paired with different pairs:
Commercial
Proceed Studying Under
# align search engines
def serps_align(okay, df):
prime_df = df.loc[df.keyword == k]
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_a", 'key phrase': 'keyword_a'})
comp_df = df.loc[df.keyword != k].reset_index(drop=True)
prime_df = prime_df.loc[prime_df.index.repeat(len(comp_df.index))].reset_index(drop=True)
prime_df = pd.concat([prime_df, comp_df], axis=1)
prime_df = prime_df.rename(columns = {"serp_string" : "serp_string_b", 'key phrase': 'keyword_b', "serp_string_a" : "serp_string", 'keyword_a': 'key phrase'})
go back prime_df
columns = ['keyword', 'serp_string', 'keyword_b', 'serp_string_b']
matched_serps = pd.DataFrame(columns=columns)
matched_serps = matched_serps.fillna(0)
queries = strung_serps.key phrase.to_list()
for q in queries:
temp_df = serps_align(q, strung_serps)
matched_serps = matched_serps.append(temp_df)
matched_serps

The above displays all the key phrase SERP pair mixtures, making it able for SERP string comparability.
There is not any open supply library that compares record gadgets by way of order, so the serve as has been written for you underneath.
Commercial
Proceed Studying Under
The serve as ‘serp_compare’ compares the overlap of web sites and the order of the ones websites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Simplest evaluate the highest k_urls effects
def serps_similarity(serps_str1, serps_str2, okay=15):
denom = okay+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
ws_tok = sm.WhitespaceTokenizer()
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
fit = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
go back intent_dist
# Follow the serve as
matched_serps['si_simi'] = matched_serps.follow(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
serps_compared = matched_serps[['keyword', 'keyword_b', 'si_simi']]
serps_compared

Now that the comparisons had been finished, we will be able to get started clustering key phrases.
Commercial
Proceed Studying Under
We will be able to be treating any key phrases that have a weighted similarity of 40% or extra.
# workforce key phrases by way of seek intent
simi_lim = 0.4
# sign up for seek quantity
keysv_df = serps_input[['keyword', 'search_volume']].drop_duplicates()
keysv_df.head()
# append matter vols
keywords_crossed_vols = serps_compared.merge(keysv_df, on = 'key phrase', how = 'left')
keywords_crossed_vols = keywords_crossed_vols.rename(columns = {'key phrase': 'matter', 'keyword_b': 'key phrase',
'search_volume': 'topic_volume'})
# sim si_simi
keywords_crossed_vols.sort_values('topic_volume', ascending = False)
# strip NANs
keywords_filtered_nonnan = keywords_crossed_vols.dropna()
keywords_filtered_nonnan
We've got the prospective matter identify, key phrases SERP similarity, and seek volumes of every.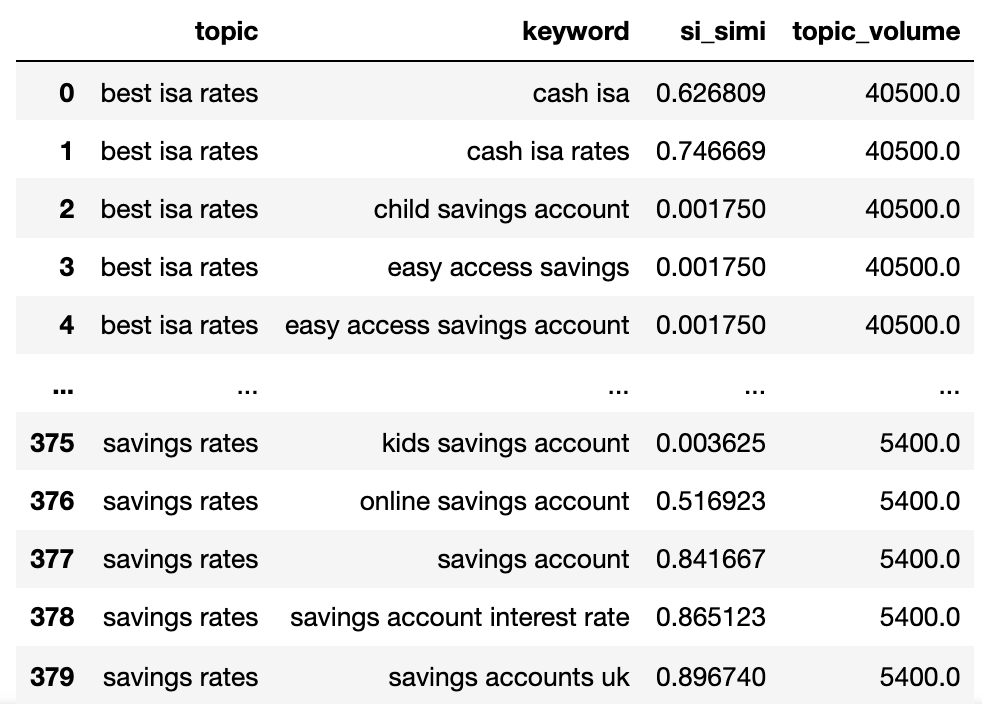
You’ll be aware that key phrase and keyword_b had been renamed to matter and key phrase, respectively.
Commercial
Proceed Studying Under
Now we’re going to iterate over the columns within the dataframe the usage of the lamdas method.
The lamdas method is a good method to iterate over rows in a Pandas dataframe as it converts rows to a listing versus the .iterrows() serve as.
Right here is going:
queries_in_df = record(set(keywords_filtered_nonnan.matter.to_list()))
topic_groups_numbered = {}
topics_added = []
def find_topics(si, keyw, topc):
i = 0
if (si >= simi_lim) and (no longer keyw in topics_added) and (no longer topc in topics_added):
i += 1
topics_added.append(keyw)
topics_added.append(topc)
topic_groups_numbered[i] = [keyw, topc]
elif si >= simi_lim and (keyw in topics_added) and (no longer topc in topics_added):
j = [key for key, value in topic_groups_numbered.items() if keyw in value]
topics_added.append(topc)
topic_groups_numbered[j[0]].append(topc)
elif si >= simi_lim and (no longer keyw in topics_added) and (topc in topics_added):
j = [key for key, value in topic_groups_numbered.items() if topc in value]
topics_added.append(keyw)
topic_groups_numbered[j[0]].append(keyw)
def apply_impl_ft(df):
go back df.follow(
lambda row:
find_topics(row.si_simi, row.key phrase, row.matter), axis=1)
apply_impl_ft(keywords_filtered_nonnan)
topic_groups_numbered = {okay:record(set(v)) for okay, v in topic_groups_numbered.pieces()}
topic_groups_numbered
Under displays a dictionary containing all of the key phrases clustered by way of seek intent into numbered teams:
{1: ['fixed rate isa',
'isa rates',
'isa interest rates',
'best isa rates',
'cash isa',
'cash isa rates'],
2: ['child savings account', 'kids savings account'],
3: ['savings account',
'savings account interest rate',
'savings rates',
'fixed rate savings',
'easy access savings',
'fixed rate bonds',
'online savings account',
'easy access savings account',
'savings accounts uk'],
4: ['isa account', 'isa', 'isa savings']}
Let’s stick that right into a dataframe:
topic_groups_lst = []
for okay, l in topic_groups_numbered.pieces():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
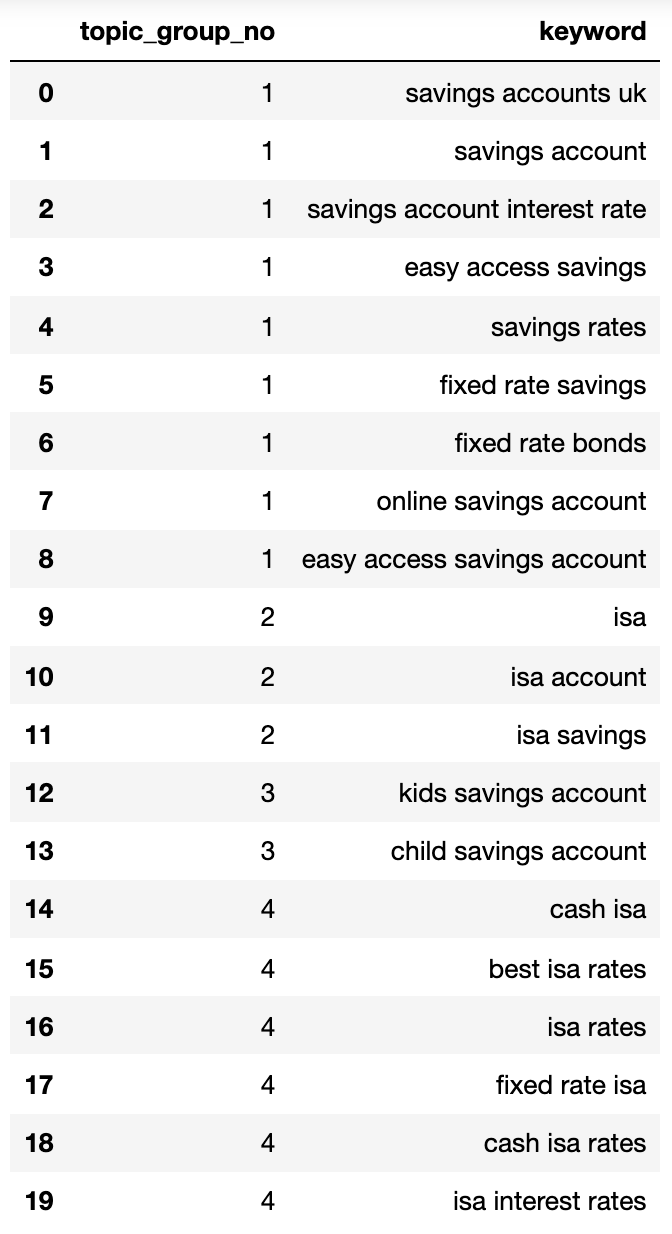
The hunt intent teams above display a just right approximation of the key phrases inside of them, one thing that an Search engine optimization professional would most probably succeed in.
Commercial
Proceed Studying Under
Even though we most effective used a small set of key phrases, the process can clearly be scaled to hundreds (if no longer extra).
Activating The Outputs To Make Your Seek Higher
After all, the above may well be taken additional the usage of neural networks processing the score content material for extra correct clusters and cluster workforce naming, as one of the crucial business merchandise available in the market already do.
For now, with this output you'll:
- Incorporate this into your personal Search engine optimization dashboard methods to make your traits and Search engine optimization reporting extra significant.
- Construct higher paid seek campaigns by way of structuring your Google Advertisements accounts by way of seek intent for a better High quality Rating.
- Merge redundant side ecommerce seek URLs.
- Construction a buying groceries web site’s taxonomy consistent with seek intent as a substitute of a normal product catalog.
Commercial
Proceed Studying Under
I’m positive there are extra programs that I haven’t discussed — be at liberty to touch upon any necessary ones that I’ve no longer already discussed.
In spite of everything, your Search engine optimization key phrase analysis simply were given that little bit extra scalable, correct, and sooner!
2021 SEJ Christmas Countdown:
Featured symbol: Astibuag/Shutterstock.com
Commercial
Proceed Studying Under
#Automate #Search engine optimization #Key phrase #Clustering #Seek #Intent #Python




