Easy methods to Do an search engine marketing Log Document Research [Template Included] #search engine marketing Information
![How to Do an SEO Log File Analysis [Template Included]](https://mycyberbase.com/wp-content/uploads/2022/04/How-to-Do-an-SEO-Log-File-Analysis-Template-Included-780x470.png)
Log information were receiving expanding reputation from technical SEOs during the last 5 years, and for a excellent reason why.
They’re probably the most faithful supply of data to grasp the URLs that engines like google have crawled, which may also be essential data to lend a hand diagnose issues of technical search engine marketing.
Google itself acknowledges their significance, freeing new options in Google Seek Console and making it simple to peer samples of knowledge that might prior to now most effective be to be had through examining logs.
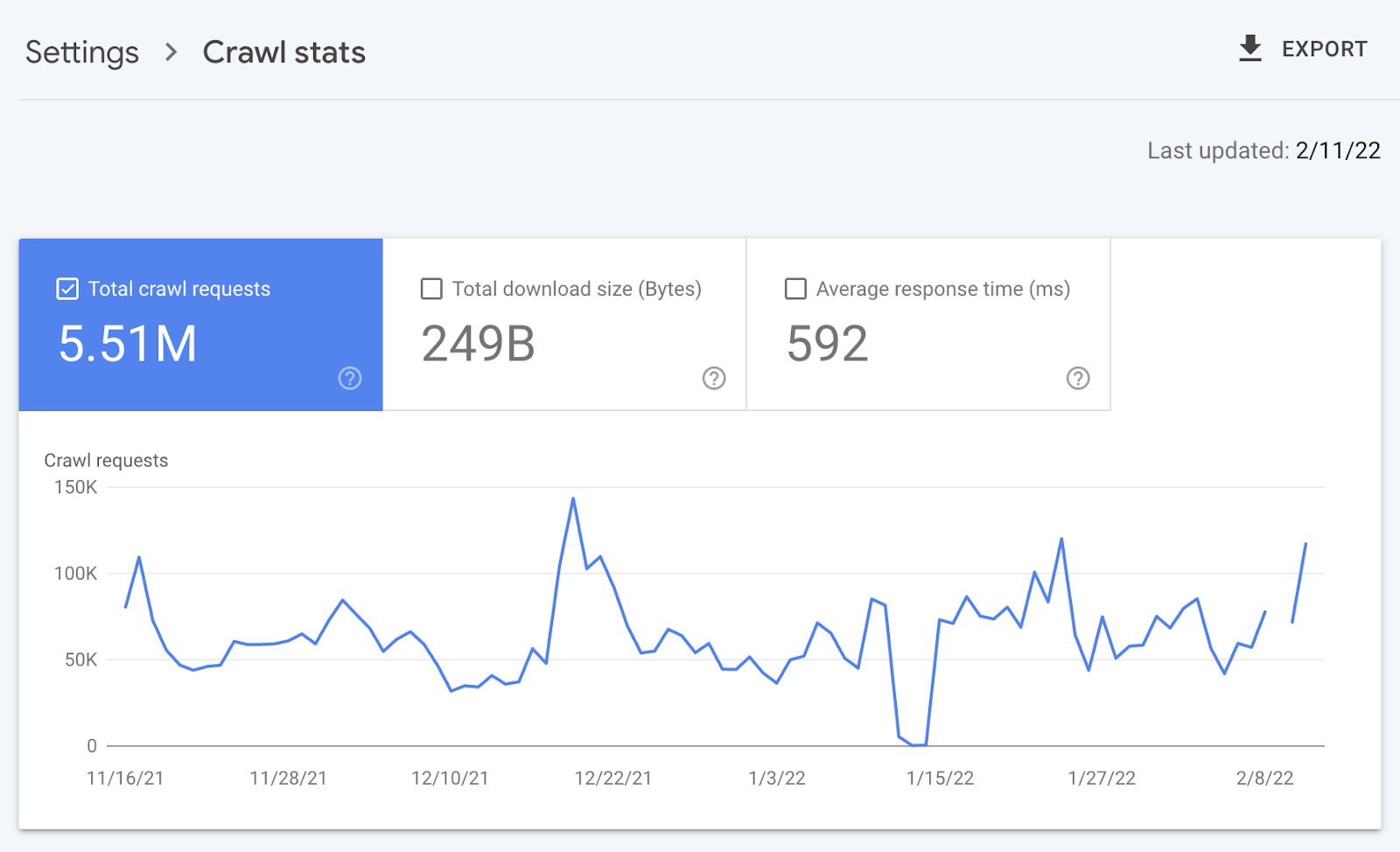
As well as, Google Seek Recommend John Mueller has publicly said how a lot excellent data log information hang.
@glenngabe Log information are so underrated, such a lot excellent data in them.
— 🦝 John (private) 🦝 (@JohnMu) April 5, 2016
With all this hype across the information in log information, you might need to perceive logs higher, methods to analyze them, and whether or not the websites you’re operating on will take pleasure in them.
This article is going to solution all of that and extra. Right here’s what we’ll be discussing:
A server log document is a document created and up to date through a server that data the actions it has carried out. A well-liked server log document is an get entry to log document, which holds a historical past of HTTP requests to the server (through each customers and bots).
When a non-developer mentions a log document, get entry to logs are those they’ll generally be regarding.
Builders, on the other hand, in finding themselves spending extra time taking a look at error logs, which file problems encountered through the server.
The above is necessary: When you request logs from a developer, the very first thing they’ll ask is, “Which of them?”
Subsequently, all the time be particular with log document requests. If you need logs to research crawling, ask for get entry to logs.
Get right of entry to log information include loads of details about each and every request made to the server, similar to the next:
- IP addresses
- Consumer brokers
- URL trail
- Timestamps (when the bot/browser made the request)
- Request sort (GET or POST)
- HTTP standing codes
What servers come with in get entry to logs varies through the server sort and occasionally what builders have configured the server to retailer in log information. Commonplace codecs for log information come with the next:
- Apache structure – That is utilized by Nginx and Apache servers.
- W3C structure – That is utilized by Microsoft IIS servers.
- ELB structure – That is utilized by Amazon Elastic Load Balancing.
- Customized codecs – Many servers give a boost to outputting a customized log structure.
Other kinds exist, however those are the primary ones you’ll come upon.
Now that we’ve were given a fundamental figuring out of log information, let’s see how they receive advantages search engine marketing.
Listed below are some key techniques:
- Move slowly tracking – You’ll be able to see the URLs engines like google move slowly and use this to identify crawler traps, glance out for move slowly price range wastage, or higher know how temporarily content material adjustments are picked up.
- Standing code reporting – That is in particular helpful for prioritizing solving mistakes. Reasonably than realizing you’ve were given a 404, you’ll be able to see exactly how repeatedly a person/seek engine is visiting the 404 URL.
- Tendencies evaluation – Via tracking crawling over the years to a URL, web page sort/website online phase, or all your website online, you’ll be able to spot adjustments and examine doable reasons.
- Orphan web page discovery – You’ll be able to cross-analyze information from log information and a website online move slowly you run your self to find orphan pages.
All websites will take pleasure in log document evaluation to a point, however the volume of receive advantages varies vastly relying on website online dimension.
That is as log information essentially receive advantages websites through serving to you higher arrange crawling. Google itself states managing the move slowly price range is one thing larger-scale or ceaselessly converting websites will take pleasure in.
The similar is right for log document evaluation.
For instance, smaller websites can most probably use the “Move slowly stats” information equipped in Google Seek Console and obtain the entire advantages discussed above—with out ever wanting to the touch a log document.
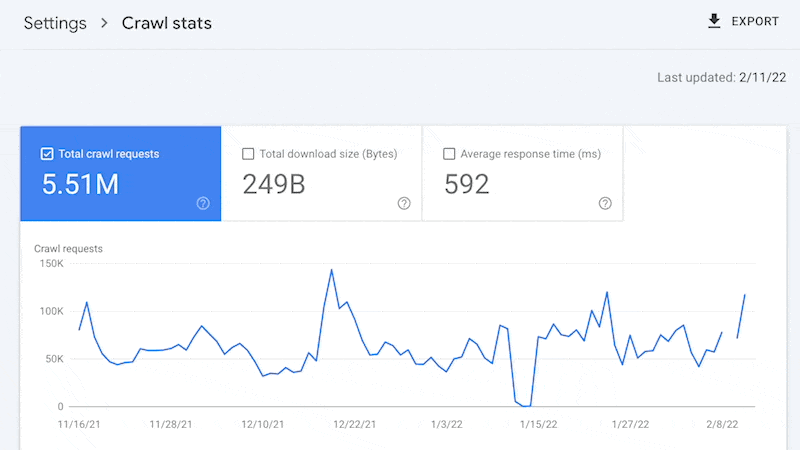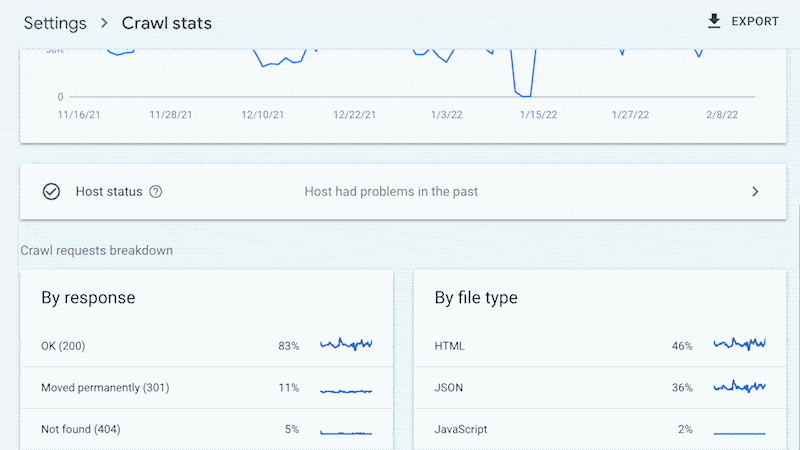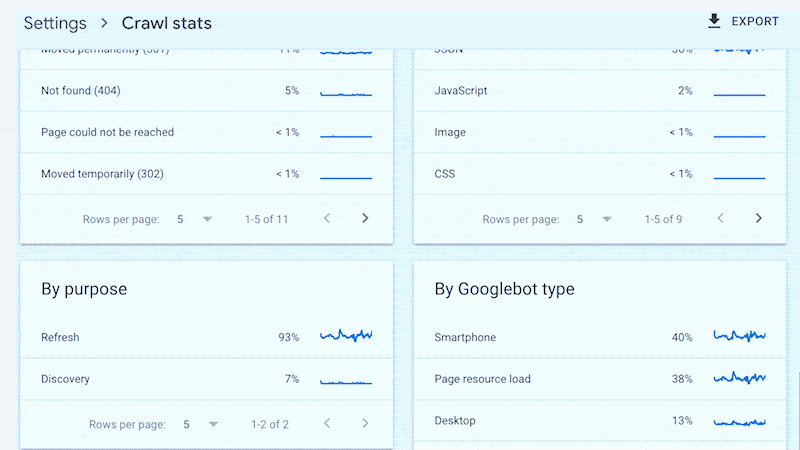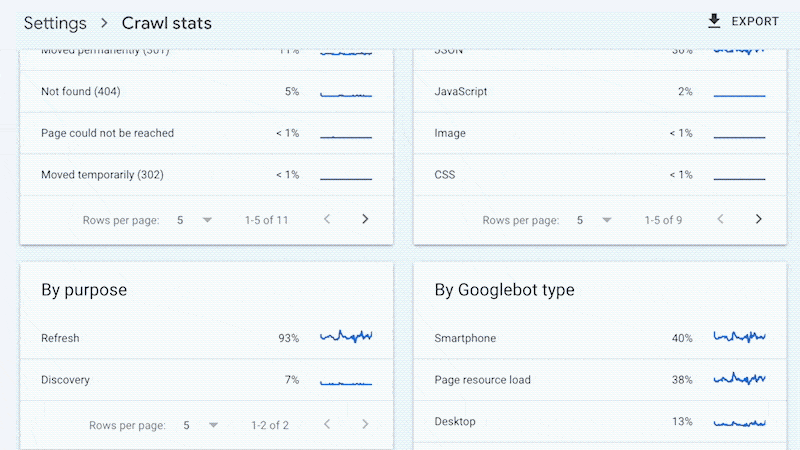
Sure, Google received’t supply you with all URLs crawled (like with log information), and the developments evaluation is proscribed to a few months of information.
Then again, smaller websites that modify sometimes additionally want much less ongoing technical search engine marketing. It’ll most probably suffice to have a website online auditor uncover and diagnose problems.
For instance, a cross-analysis from a website online crawler, XML sitemaps, Google Analytics, and Google Seek Console will most probably uncover all orphan pages.
You’ll be able to additionally use a website online auditor to find error standing codes from inner hyperlinks.
There are a couple of key causes I’m pointing this out:
- Get right of entry to log information aren’t simple to come up with (extra in this subsequent).
- For small websites that modify sometimes, the advantage of log information isn’t as a lot, which means search engine marketing focuses will most probably pass in other places.
Normally, to research log information, you’ll first must request get entry to to log information from a developer.
The developer is then most probably going to have a couple of problems, which they’ll carry for your consideration. Those come with:
- Partial information – Log information can come with partial information scattered throughout a couple of servers. This generally occurs when builders use more than a few servers, similar to an starting place server, load balancers, and a CDN. Getting a correct image of all logs will most probably imply compiling the get entry to logs from all servers.
- Document dimension – Get right of entry to log information for high-traffic websites can finally end up in terabytes, if no longer petabytes, making them arduous to switch.
- Privateness/compliance – Log information come with person IP addresses that are for my part identifiable data (PII). Consumer data would possibly want getting rid of prior to it may also be shared with you.
- Garage historical past – Because of document dimension, builders could have configured get entry to logs to be saved for a couple of days most effective, making them no longer helpful for recognizing developments and problems.
Those problems will carry to query whether or not storing, merging, filtering, and moving log information are well worth the dev effort, particularly if builders have already got a protracted checklist of priorities (which is steadily the case).
Builders will most probably put the onus at the search engine marketing to give an explanation for/construct a case for why builders must make investments time on this, which it is very important prioritize amongst different search engine marketing focuses.
Those problems are exactly why log document evaluation doesn’t occur ceaselessly.
Log information you obtain from builders also are steadily formatted in unsupported techniques through common log document evaluation gear, making evaluation tougher.
Fortunately, there are instrument answers that simplify this procedure. My favourite is Logflare, a Cloudflare app that may retailer log information in a BigQuery database that you just personal.
Now it’s time to begin examining your logs.
I’m going to turn you ways to try this within the context of Logflare in particular; on the other hand, the recommendations on methods to use log information will paintings with any logs.
The template I’ll proportion in a while additionally works with any logs. You’ll simply want to be sure that the columns within the information sheets fit up.
1. Get started through putting in Logflare (non-compulsory)
Logflare is inconspicuous to arrange. And with the BigQuery integration, it retail outlets information lengthy time period. You’ll personal the information, making it simply obtainable for everybody.
There’s one issue. You want to switch out your area title servers to make use of Cloudflare ones and arrange your DNS there.
For many, that is tremendous. Then again, for those who’re operating with a extra enterprise-level website online, it’s not going you’ll be able to persuade the server infrastructure crew to modify the title servers to simplify log evaluation.
I received’t pass via each step on methods to get Logflare operating. However to get began, all you want to do is head to the Cloudflare Apps a part of your dashboard.
After which seek for Logflare.
The setup previous this level is self-explanatory (create an account, give your challenge a reputation, make a choice the information to ship, and many others.). The one further phase I like to recommend following is Logflare’s information to putting in BigQuery.
Take into accout, on the other hand, that BigQuery does have a price that’s according to the queries you do and the volume of knowledge you retailer.
Sidenote.
It’s value noting that one important good thing about the BigQuery backend is that you just personal the information. That implies you’ll be able to circumvent PII problems through configuring Logflare to not ship PII like IP addresses and delete PII from BigQuery the use of an SQL question.
2. Test Googlebot
We’ve now saved log information (by means of Logflare or another manner). Subsequent, we want to extract logs exactly from the person brokers we need to analyze. For many, this might be Googlebot.
Sooner than we do this, we’ve got some other hurdle to leap throughout.
Many bots fake to be Googlebot to get previous firewalls (you probably have one). As well as, some auditing gear do the similar to get a correct mirrored image of the content material your website online returns for the person agent, which is very important in case your server returns other HTML for Googlebot, e.g., for those who’ve arrange dynamic rendering.
I’m no longer the use of Logflare
When you aren’t the use of Logflare, figuring out Googlebot would require a opposite DNS look up to ensure the request did come from Google.
Google has a to hand information on validating Googlebot manually right here.
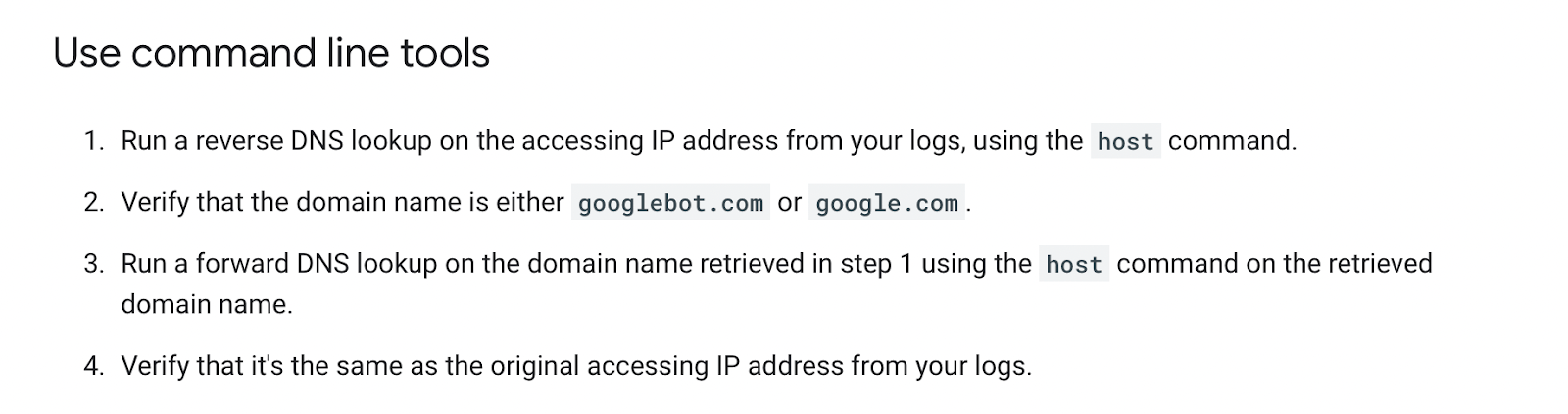
You’ll be able to do that on a one-off foundation, the use of a opposite IP look up device and checking the area title returned.
Then again, we want to do that in bulk for all rows in our log information. This additionally calls for you to compare IP addresses from a listing equipped through Google.
One of the simplest ways to try this is through the use of server firewall rule units maintained through 3rd events that block pretend bots (leading to fewer/no pretend Googlebots on your log information). A common one for Nginx is “Nginx Final Dangerous Bot Blocker.”
Then again, one thing you’ll be aware at the checklist of Googlebot IPs is the IPV4 addresses all start with “66.”
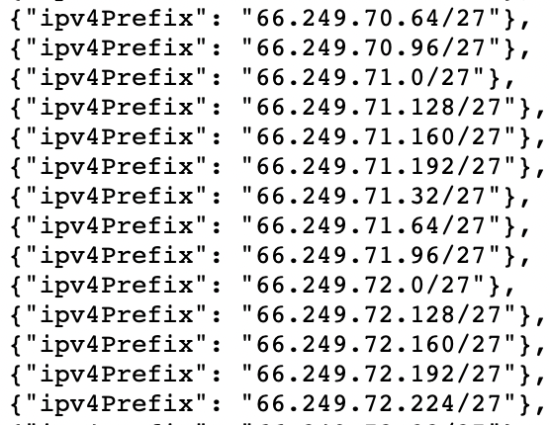
Whilst it received’t be 100% correct, you’ll be able to additionally test for Googlebot through filtering for IP addresses beginning with “6” when examining the information inside your logs.
I’m the use of Cloudflare/Logflare
Cloudflare’s professional plan (lately $20/month) has integrated firewall options that may block pretend Googlebot requests from gaining access to your website online.
Cloudflare disables those options through default, however you’ll be able to in finding them through heading to Firewall > Controlled Laws > enabling “Cloudflare Specials” > make a selection “Complicated”:

Subsequent, exchange the hunt sort from “Description” to “ID” and seek for “100035.”
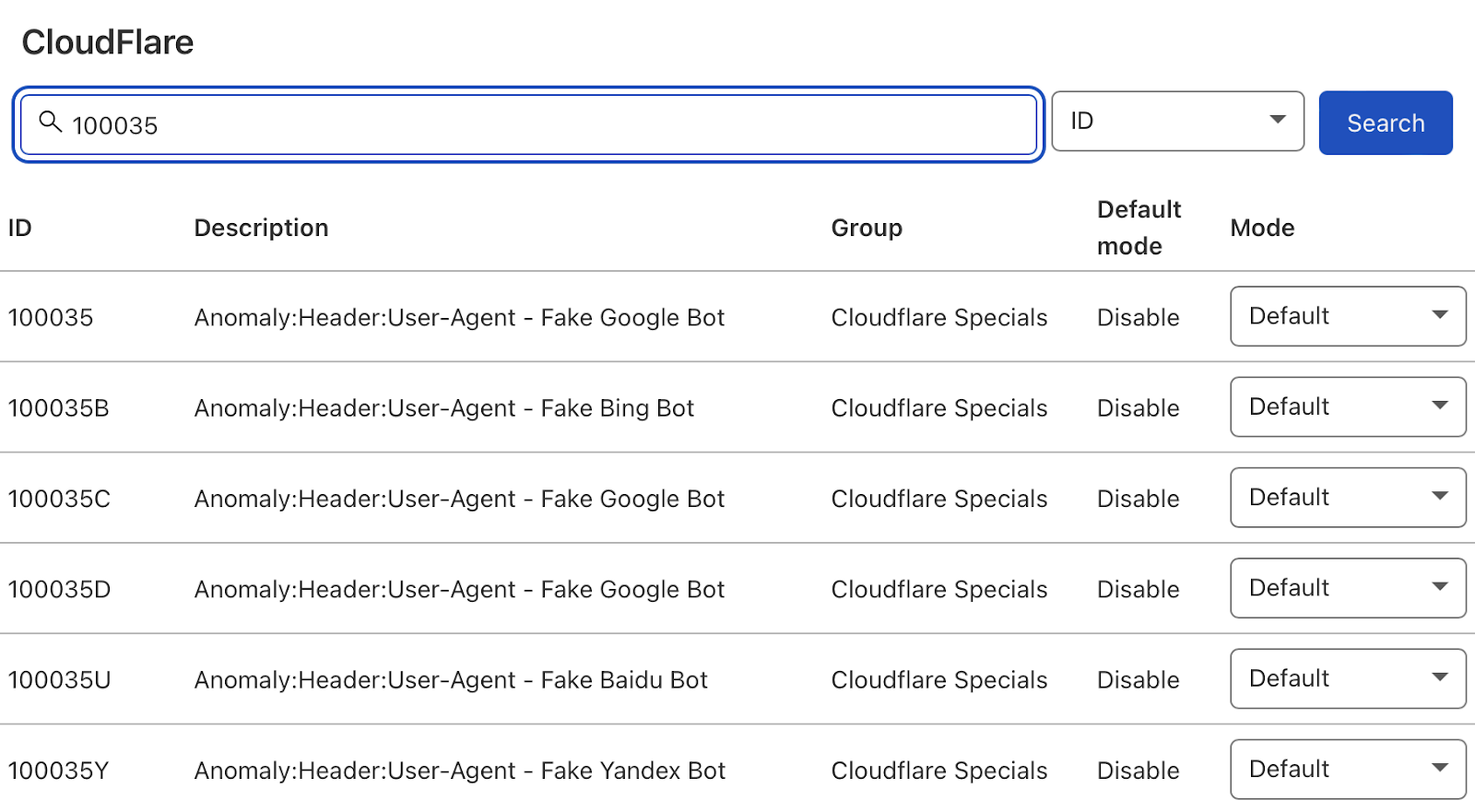
Cloudflare will now provide you with a listing of choices to dam pretend seek bots. Set the related ones to “Block,” and Cloudflare will test all requests from seek bot person brokers are official, maintaining your log information blank.
3. Extract information from log information
In any case, we’ve get entry to to log information, and we all know the log information as it should be mirror authentic Googlebot requests.
I like to recommend examining your log information inside Google Sheets/Excel to begin with as a result of you’ll most probably be used to spreadsheets, and it’s easy to cross-analyze log information with different assets like a website online move slowly.
There is not any one proper means to try this. You’ll be able to use the next:
You’ll be able to additionally do that inside a Information Studio file. I in finding Information Studio useful for tracking information over the years, and Google Sheets/Excel is healthier for a one-off evaluation when technical auditing.
Open BigQuery and head for your challenge/dataset.
Choose the “Question” dropdown and open it in a brand new tab.
Subsequent, you’ll want to write some SQL to extract the information you’ll be examining. To make this more straightforward, first replica the contents of the FROM a part of the question.

After which you’ll be able to upload that inside the question I’ve written for you beneath:
SELECT DATE(timestamp) AS Date, req.url AS URL, req_headers.cf_connecting_ip AS IP, req_headers.user_agent AS User_Agent, resp.status_code AS Status_Code, resp.origin_time AS Origin_Time, resp_headers.cf_cache_status AS Cache_Status, resp_headers.content_type AS Content_Type
FROM `[Add Your from address here]`,
UNNEST(metadata) m,
UNNEST(m.request) req,
UNNEST(req.headers) req_headers,
UNNEST(m.reaction) resp,
UNNEST(resp.headers) resp_headers
WHERE DATE(timestamp) >= "2022-01-03" AND (req_headers.user_agent LIKE '%Googlebot%' OR req_headers.user_agent LIKE '%bingbot%')
ORDER BY timestamp DESC
This question selects all of the columns of knowledge which can be helpful for log document evaluation for search engine marketing functions. It additionally most effective pulls information for Googlebot and Bingbot.
Sidenote.
If there are different bots you need to research, simply upload some other OR req_headers.user_agent LIKE ‘%bot_name%’ inside the WHERE commentary. You’ll be able to additionally simply exchange the beginning date through updating the WHERE DATE(timestamp) >= “2022–03-03” line.
Choose “Run” on the best. Then make a choice to save lots of the effects.
Subsequent, save the information to a CSV in Google Power (that is the most suitable choice because of the bigger document dimension).
After which, as soon as BigQuery has run the task and stored the document, open the document with Google Sheets.
4. Upload to Google Sheets
We’re now going to begin with some evaluation. I like to recommend the use of my Google Sheets template. However I’ll provide an explanation for what I’m doing, and you’ll be able to construct the file your self for those who need.
This is my template.
The template is composed of 2 information tabs to duplicate and paste your information into, which I then use for all different tabs the use of the Google Sheets QUERY serve as.
Sidenote.
If you wish to see how I’ve finished the reviews that we’ll run via after putting in, make a selection the primary cellular in each and every desk.
First of all, replica and paste the output of your export from BigQuery into the “Information — Log information” tab.
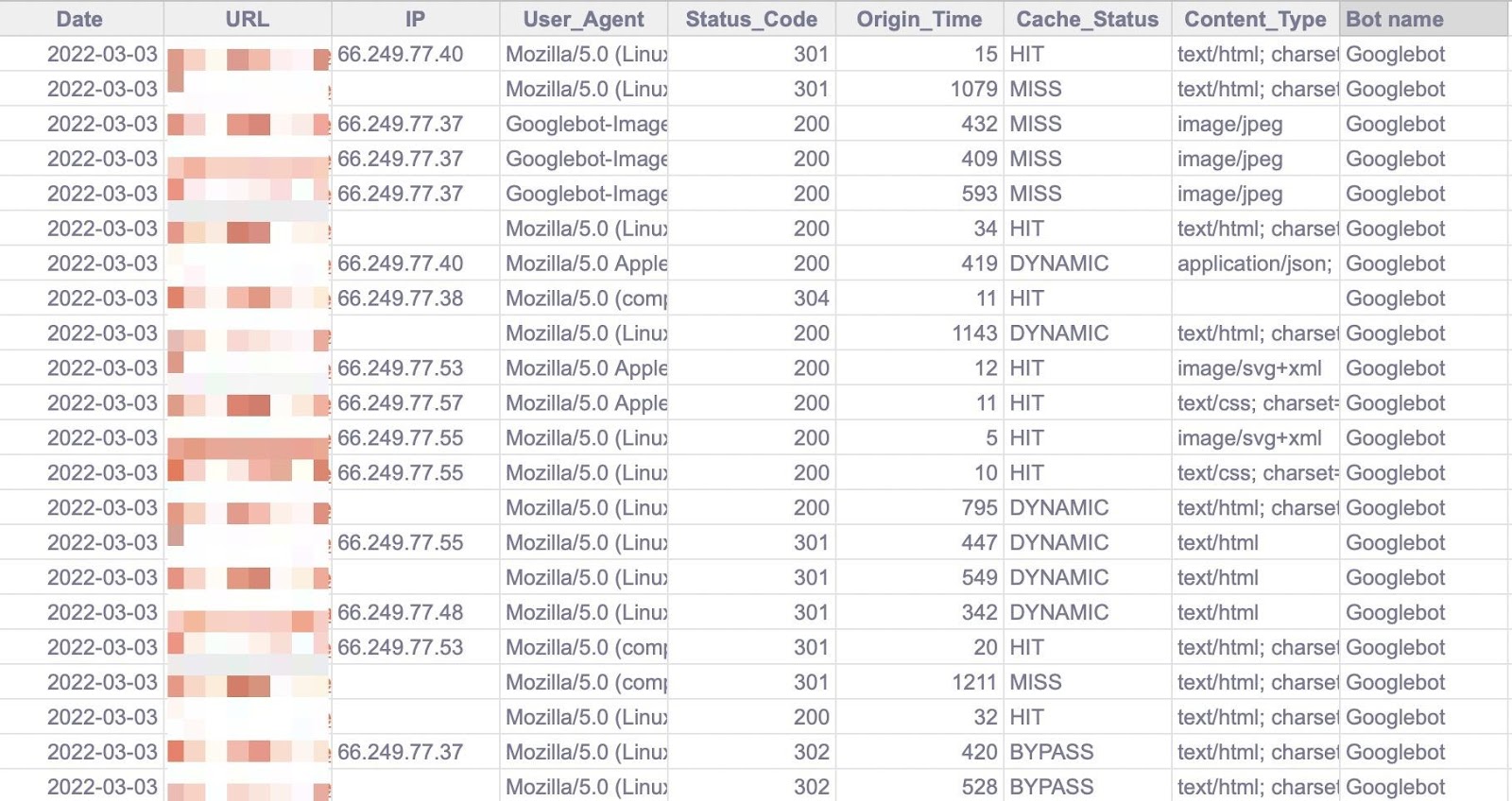
Notice that there are a couple of columns added to the tip of the sheet (in darker gray) to make evaluation just a little more straightforward (just like the bot title and first URL listing).
5. Upload Ahrefs information
When you’ve got a website online auditor, I like to recommend including extra information to the Google Sheet. Basically, you must upload those:
- Natural site visitors
- Standing codes
- Move slowly intensity
- Indexability
- Choice of inner hyperlinks
To get this information out of Ahrefs’ Web page Audit, head to Web page Explorer and make a selection “Organize Columns.”
I then counsel including the columns proven beneath:
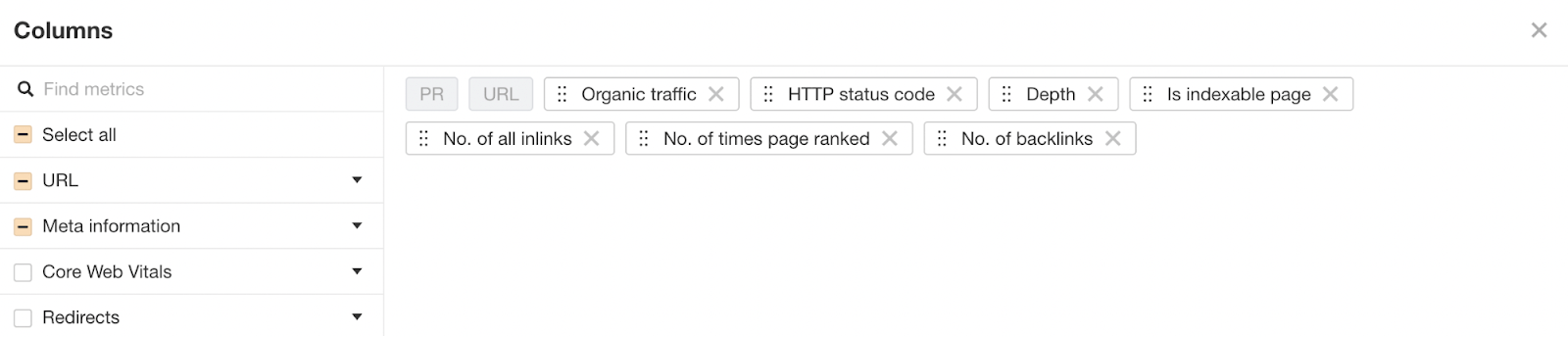
Then export all of that information.
And duplicate and paste into the “Information — Ahrefs” sheet.
6. Take a look at for standing codes
The very first thing we’ll analyze is standing codes. This knowledge will solution whether or not seek bots are losing move slowly price range on non-200 URLs.
Notice that this doesn’t all the time level towards an factor.
Every so often, Google can move slowly outdated 301s for a few years. Then again, it might spotlight a subject for those who’re internally linking to many non-200 standing codes.
The “Standing Codes — Assessment” tab has a QUERY serve as that summarizes the log document information and presentations the leads to a chart.
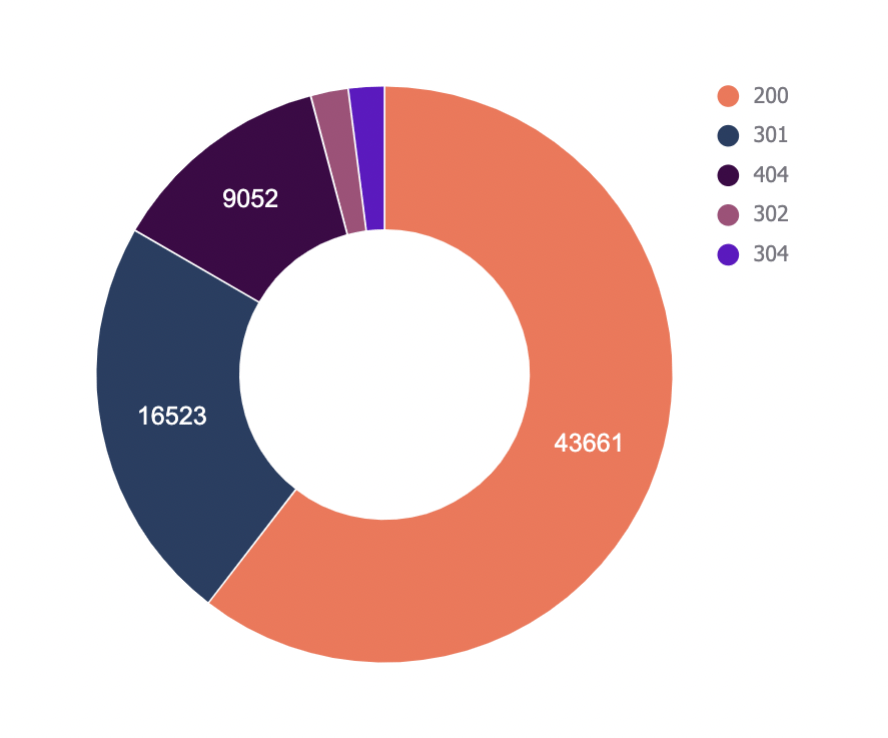
There could also be a dropdown to filter out through bot sort and see which of them are hitting non-200 standing codes the maximum.
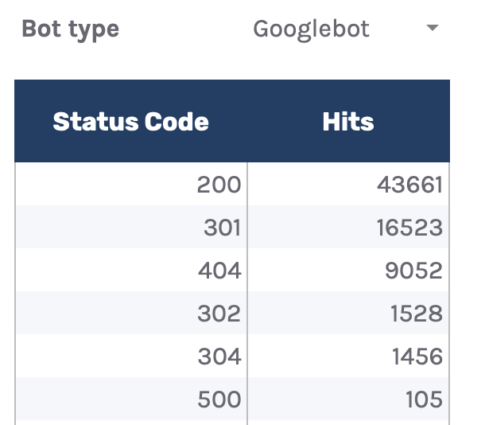
In fact, this file on my own doesn’t lend a hand us resolve the problem, so I’ve added some other tab, “URLs — Assessment.”
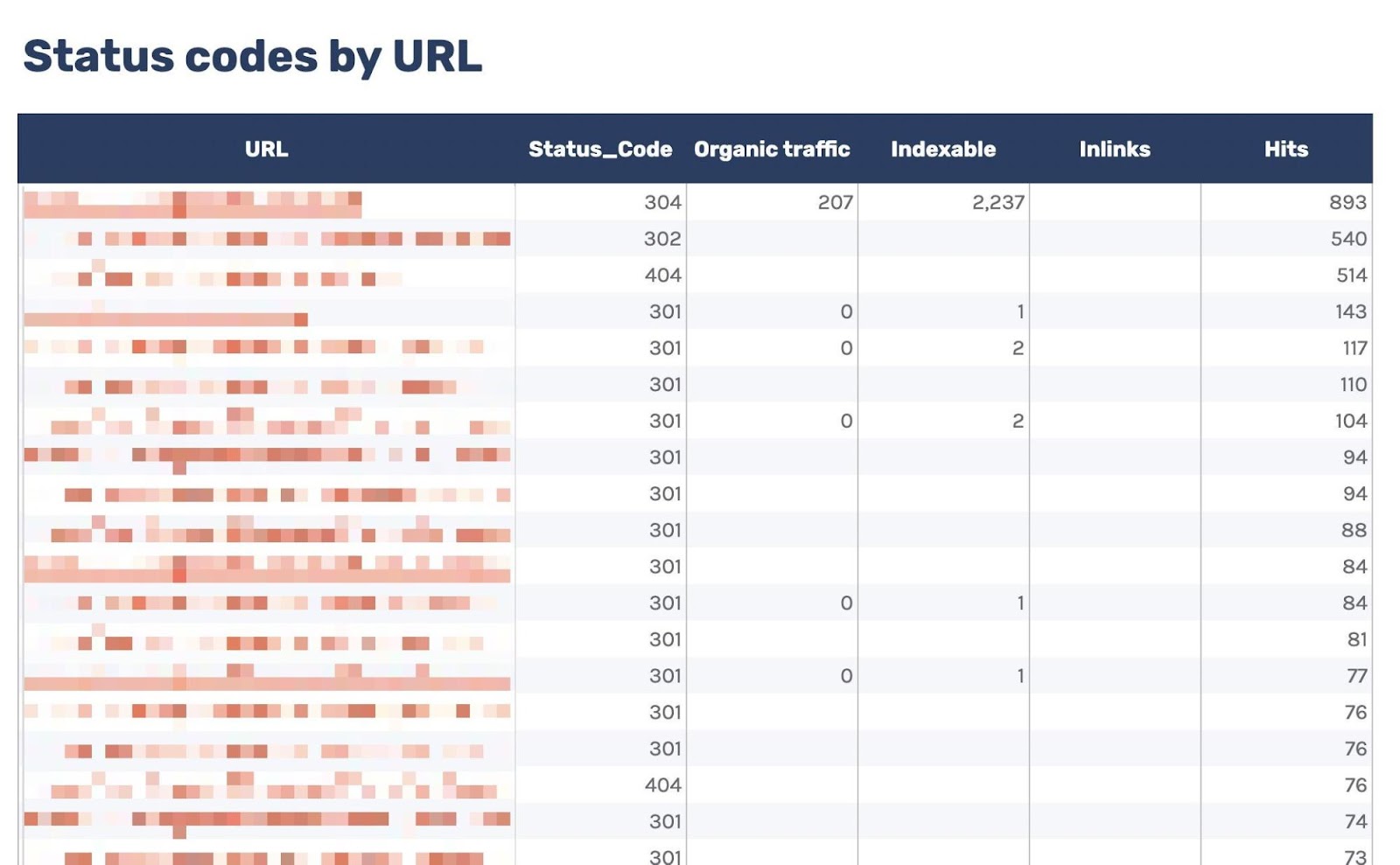
You’ll be able to use this to filter out for URLs that go back non-200 standing codes. As I’ve additionally integrated information from Ahrefs’ Web page Audit, you’ll be able to see whether or not you’re internally linking to any of the ones non-200 URLs within the “Inlinks” column.
When you see a large number of inner hyperlinks to the URL, you’ll be able to then use the Inner hyperlink alternatives file to identify those flawed inner hyperlinks through merely copying and pasting the URL within the seek bar with “Goal web page” decided on.
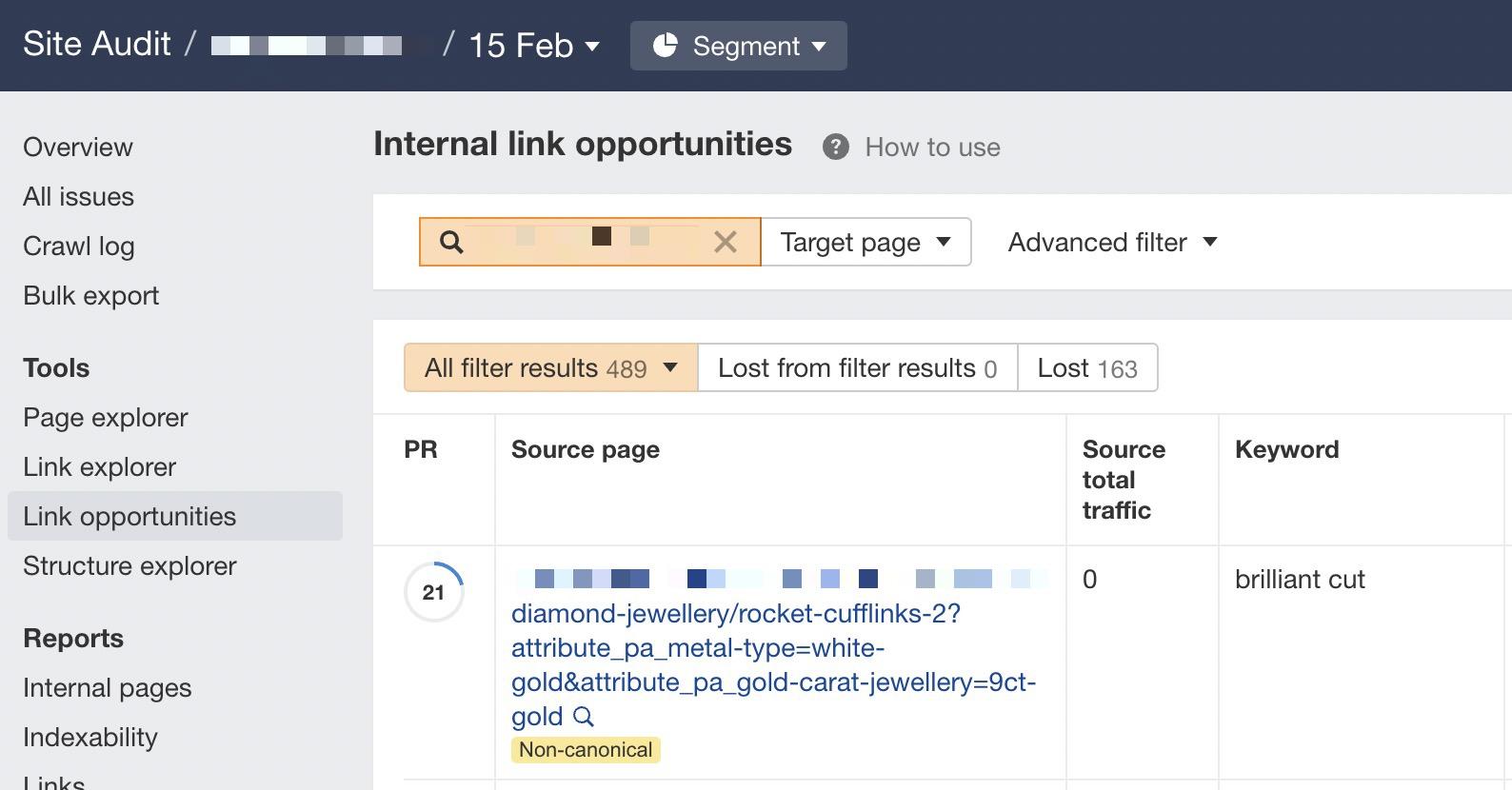
7. Stumble on move slowly price range wastage
One of the simplest ways to focus on move slowly price range wastage from log information that isn’t because of crawling non-200 standing codes is to seek out ceaselessly crawled non-indexable URLs (e.g., they’re canonicalized or noindexed).
Since we’ve added information from our log information and Ahrefs’ Web page Audit, recognizing those URLs is easy.
Head to the “Move slowly price range wastage” tab, and also you’ll in finding extremely crawled HTML information that go back a 200 however are non-indexable.
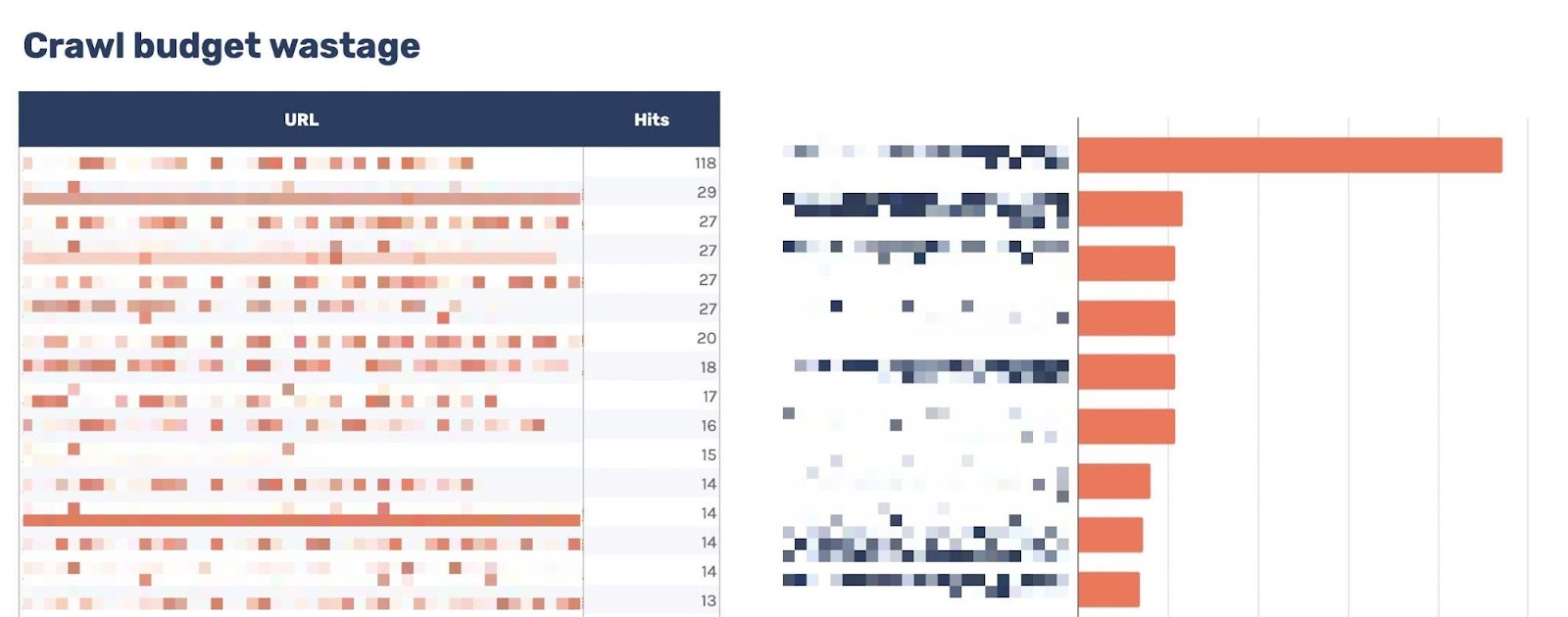
Now that you’ve this information, you’ll need to examine why the bot is crawling the URL. Listed below are some commonplace causes:
- It’s internally connected to.
- It’s incorrectly integrated in XML sitemaps.
- It has hyperlinks from exterior websites.
It’s commonplace for greater websites, particularly the ones with faceted navigation, to hyperlink to many non-indexable URLs internally.
If the hit numbers on this file are very excessive and also you imagine you’re squandering precious move slowly price range, you’ll most probably want to take away inner hyperlinks to the URLs or block crawling with the robots.txt.
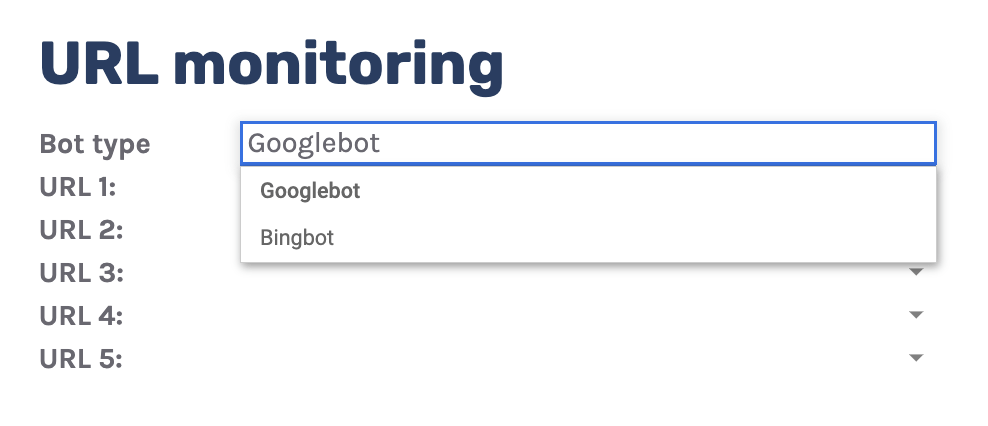
8. Track necessary URLs
When you’ve got particular URLs in your website online which can be extremely necessary to you, you might need to watch how steadily engines like google move slowly them.
The “URL observe” tab does simply that, plotting the day-to-day development of hits for as much as 5 URLs that you’ll be able to upload.
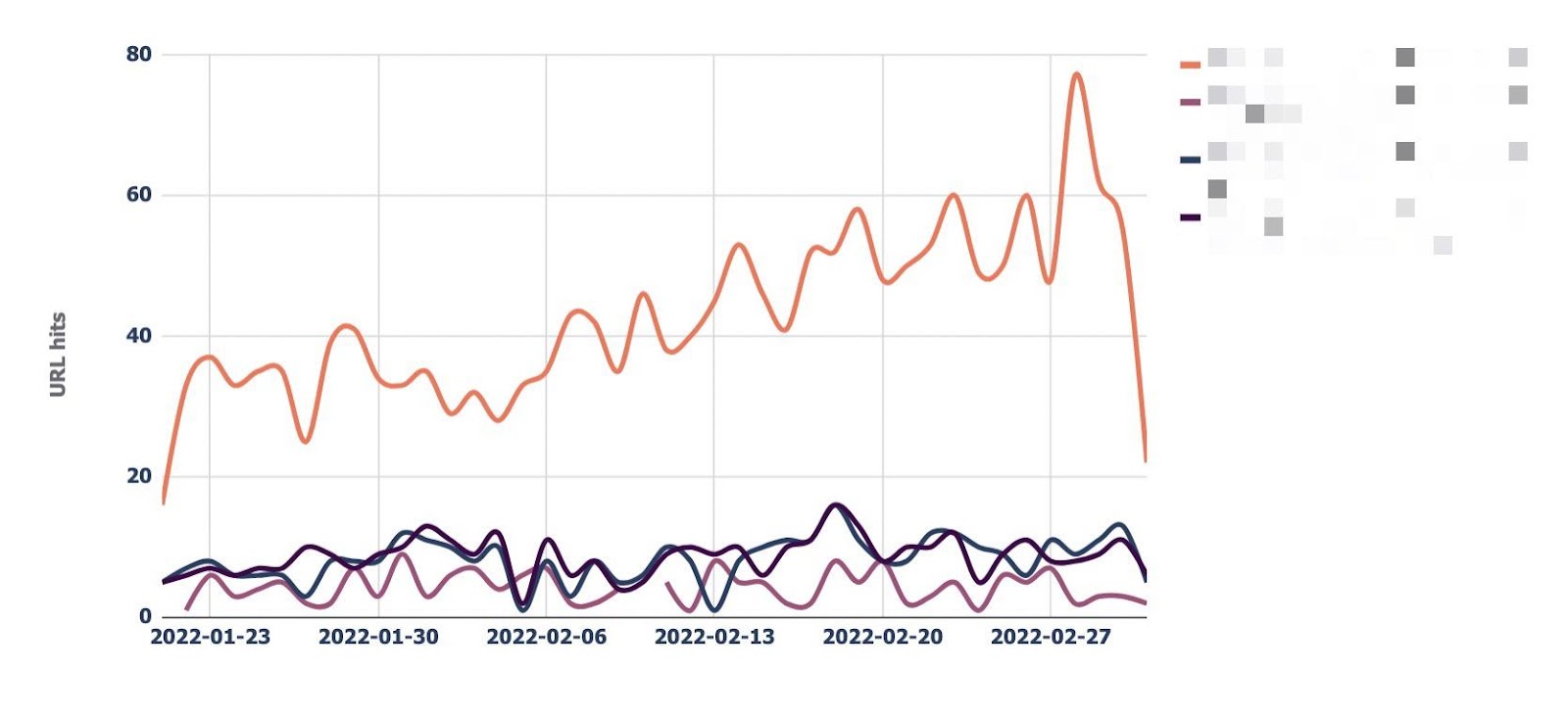
You’ll be able to additionally filter out through bot sort, making it simple to watch how steadily Bing or Google crawls a URL.
Sidenote.
You’ll be able to additionally use this file to test URLs you’ve just lately redirected. Merely upload the outdated URL and new URL within the dropdown and notice how temporarily Googlebot notices the exchange.
Continuously, the recommendation here’s that it’s a foul factor if Google doesn’t move slowly a URL ceaselessly. That merely isn’t the case.
Whilst Google has a tendency to move slowly common URLs extra ceaselessly, it is going to most probably move slowly a URL much less if it doesn’t exchange steadily.
Nonetheless, it’s useful to observe URLs like this if you want content material adjustments picked up temporarily, similar to on a information website online’s homepage.
Actually, for those who realize Google is recrawling a URL too ceaselessly, I’ll suggest for seeking to lend a hand it higher arrange move slowly charge through doing such things as including
You’ll be able to then replace the
9. To find orphan URLs
In a different way to make use of log information is to find orphan URLs, i.e., URLs that you need engines like google to move slowly and index however haven’t internally connected to.
We will do that through checking for 200 standing code HTML URLs without a inner hyperlinks discovered through Ahrefs’ Web page Audit.
You’ll be able to see the file I’ve created for this named “Orphan URLs.”
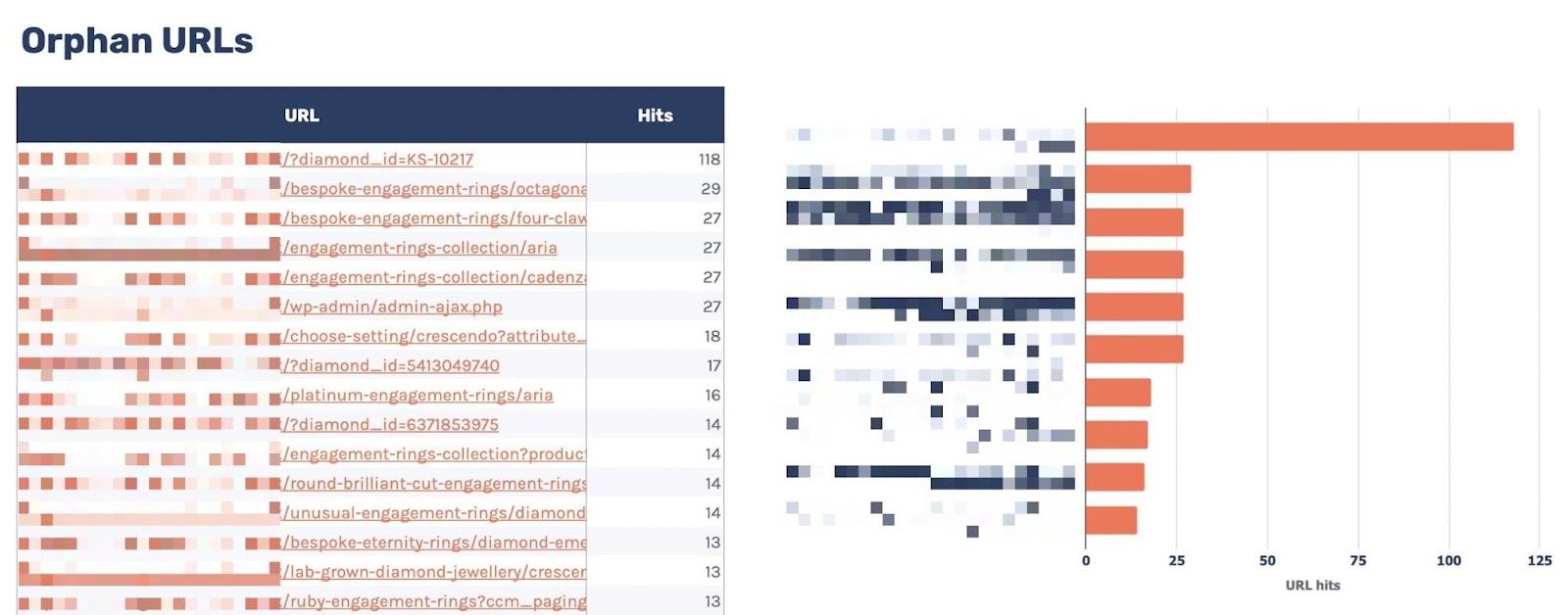
There’s one caveat right here. As Ahrefs hasn’t came upon those URLs however Googlebot has, those URLs might not be URLs we need to hyperlink to as a result of they’re non-indexable.
I like to recommend copying and pasting those URLs the use of the “Customized URL checklist” capability when putting in move slowly assets to your Ahrefs challenge.
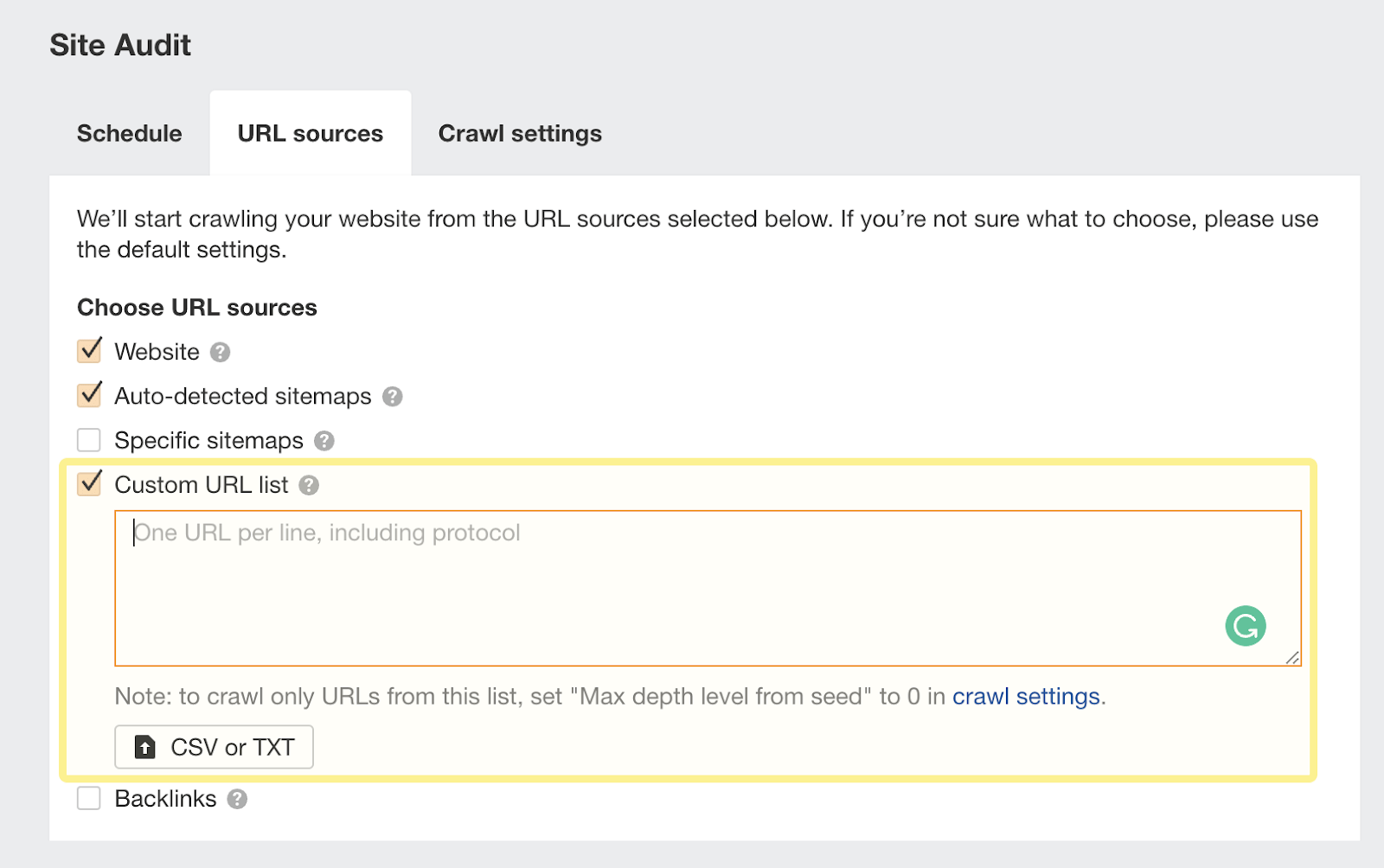
This manner, Ahrefs will now believe those orphan URLs discovered on your log information and file any problems to you on your subsequent move slowly:

10. Track crawling through listing
Assume you’ve carried out structured URLs that point out the way you’ve arranged your website online (e.g., /options/feature-page/).
If so, you’ll be able to additionally analyze log information according to the listing to peer if Googlebot is crawling sure sections of the website online greater than others.
I’ve carried out this type of evaluation within the “Directories — Assessment” tab of the Google Sheet.
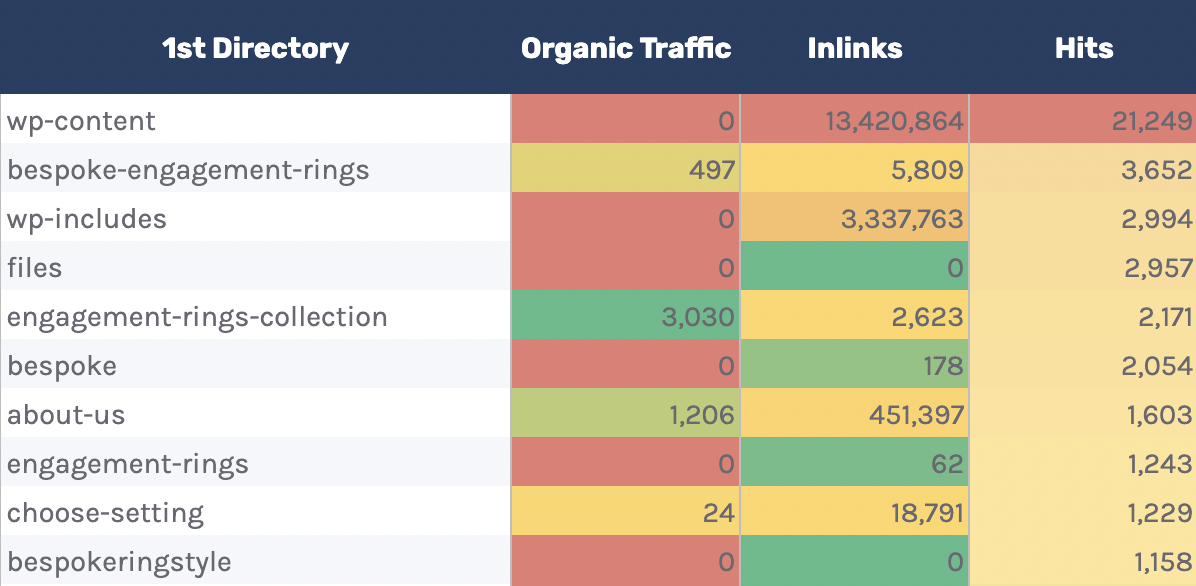
You’ll be able to see I’ve additionally integrated information at the collection of inner hyperlinks to the directories, in addition to overall natural site visitors.
You’ll be able to use this to peer whether or not Googlebot is spending extra time crawling low-traffic directories than high-value ones.
However once more, keep in mind this will likely happen, as some URLs inside particular directories exchange extra steadily than others. Nonetheless, it’s value additional investigating for those who spot an abnormal development.
Along with this file, there could also be a “Directories — Move slowly development” file if you wish to see the move slowly development in line with listing to your website online.
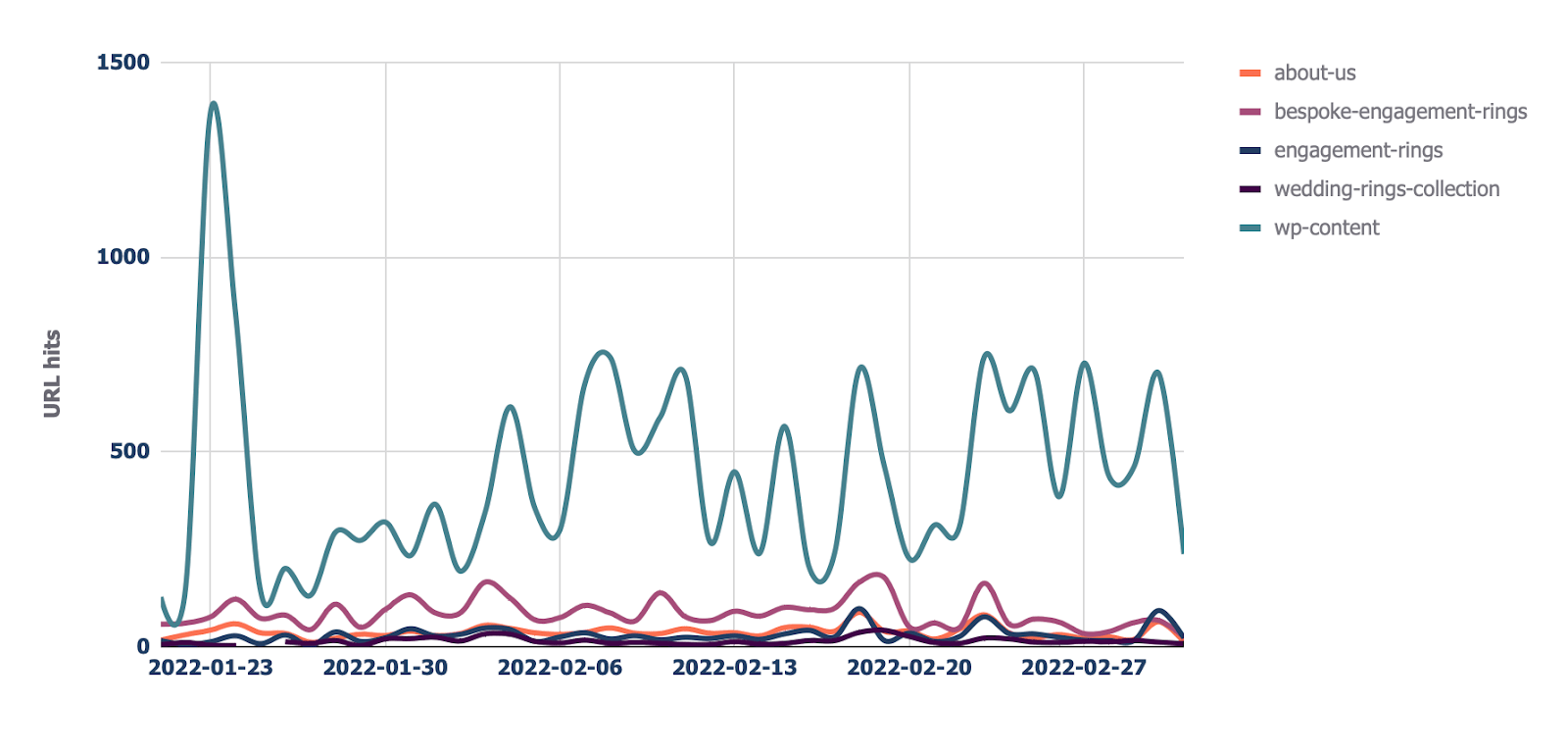
11. View Cloudflare cache ratios
Head to the “CF cache standing” tab, and also you’ll see a abstract of ways steadily Cloudflare is caching your information at the edge servers.
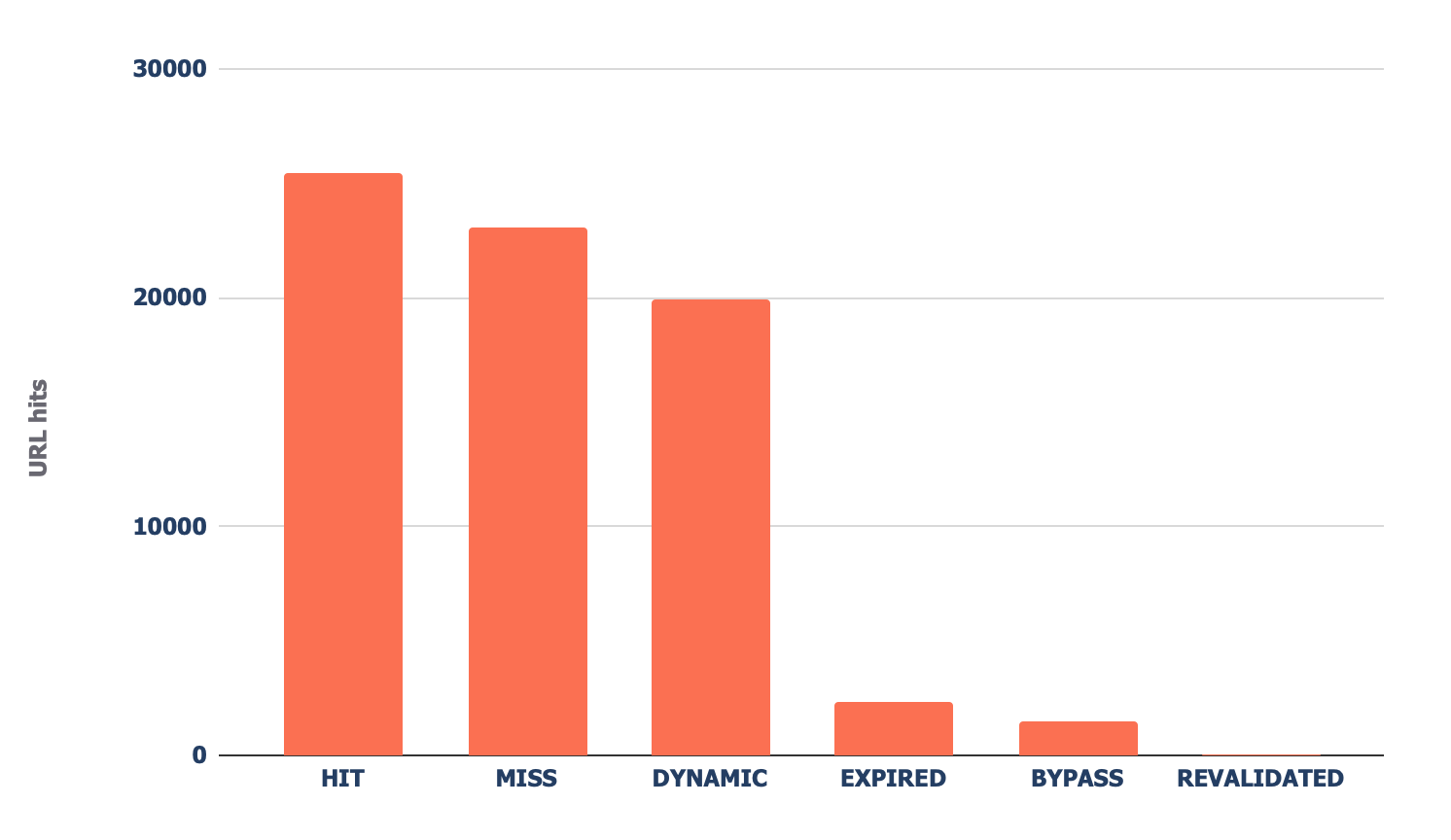
When Cloudflare caches content material (HIT within the above chart), the request now not is going for your starting place server and is served at once from its world CDN. This leads to higher Core Internet Vitals, particularly for world websites.
Sidenote.
It’s additionally value having a caching setup in your starting place server (similar to Varnish, Nginx FastCGI, or Redis full-page cache). That is in order that even if Cloudflare hasn’t cached a URL, you’ll nonetheless take pleasure in some caching.
When you see a considerable amount of “Leave out” or “Dynamic” responses, I like to recommend investigating additional to grasp why Cloudflare isn’t caching content material. Commonplace reasons can be:
- You’re linking to URLs with parameters in them – Cloudflare, through default, passes those requests for your starting place server, as they’re most probably dynamic.
- Your cache expiry instances are too low – When you set brief cache lifespans, it’s most probably extra customers will obtain uncached content material.
- You aren’t preloading your cache – If you want your cache to run out steadily (as content material adjustments ceaselessly), somewhat than letting customers hit uncached URLs, use a preloader bot that can high the cache, similar to Optimus Cache Preloader.
Sidenote.
I totally counsel putting in HTML edge-caching by means of Cloudflare, which considerably reduces TTFB. You’ll be able to do that simply with WordPress and Cloudflare’s Automated Platform Optimization.
12. Take a look at which bots move slowly your website online the maximum
The overall file (discovered within the “Bots — Assessment” tab) presentations you which of them bots move slowly your website online the maximum:
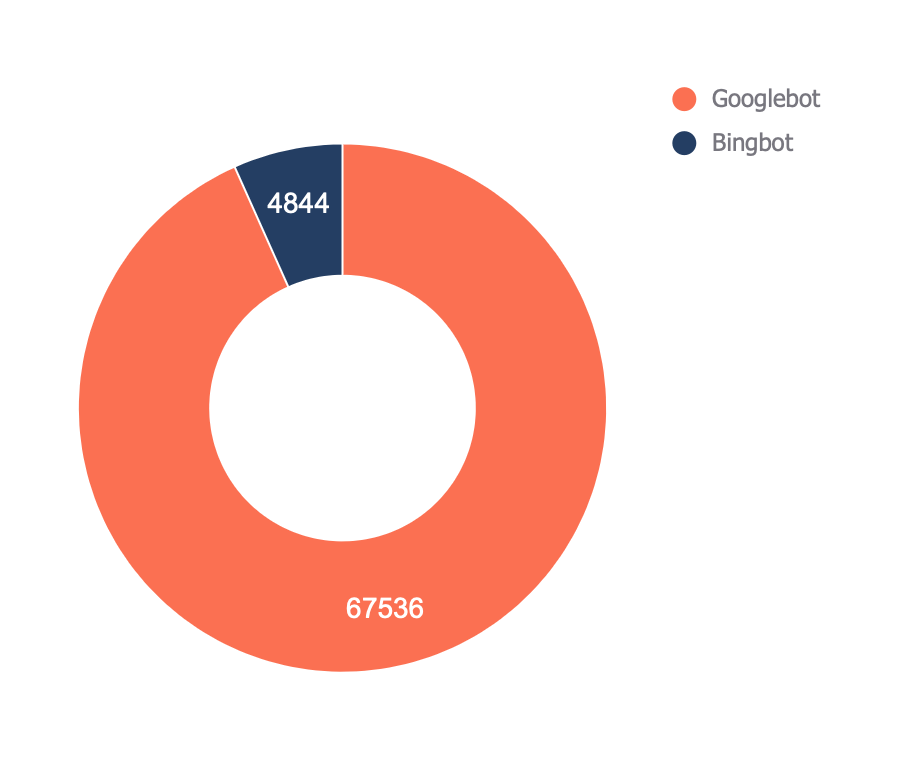
Within the “Bots — Move slowly development” file, you’ll be able to see how that development has modified over time.
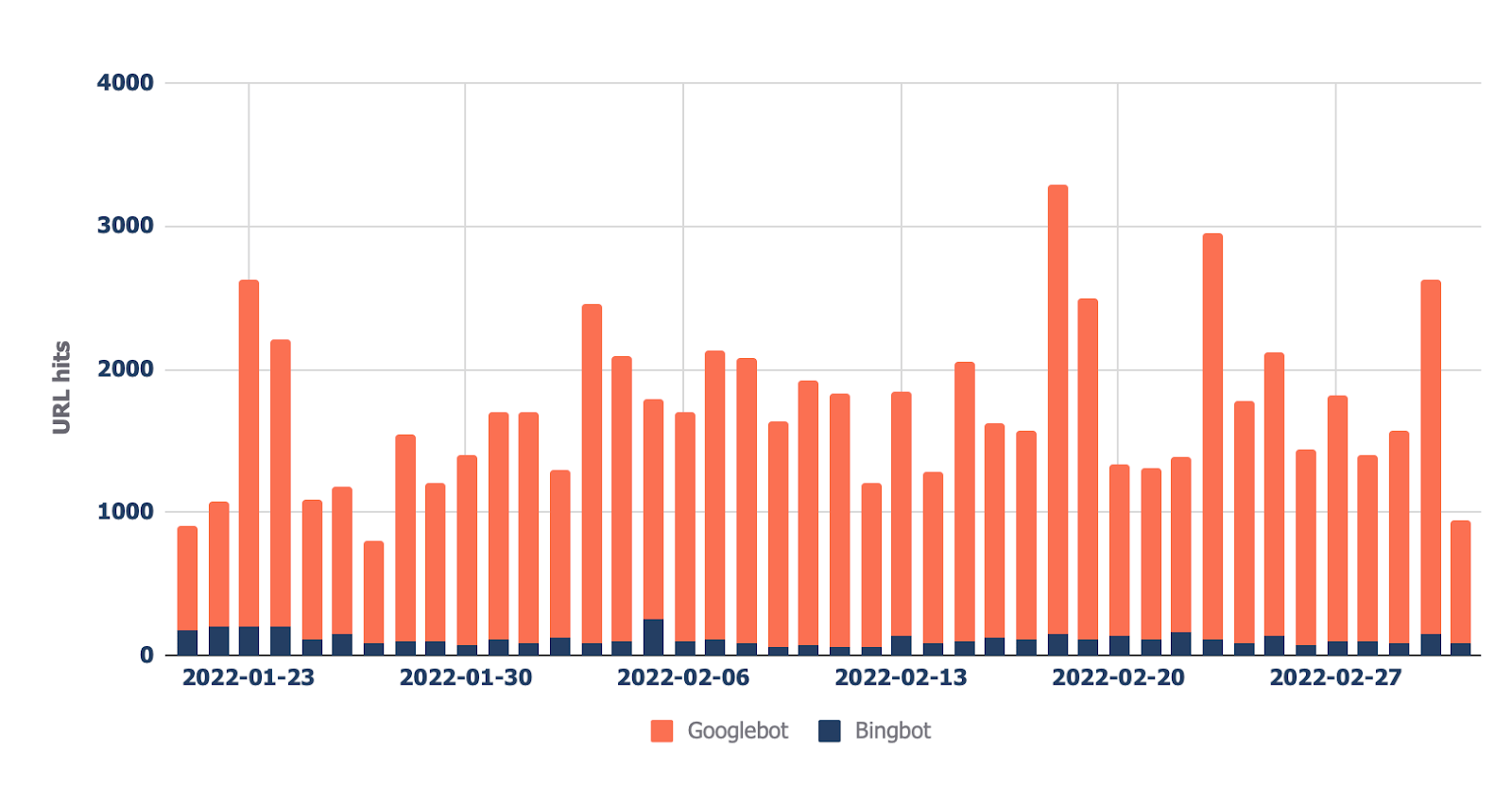
This file can lend a hand test if there’s an build up in bot process in your website online. It’s additionally useful when you’ve just lately made a vital exchange, similar to a URL migration, and need to see if bots have greater their crawling to gather new information.
Ultimate ideas
You must now have a good suggestion of the evaluation you’ll be able to do along with your log information when auditing a website online. Optimistically, you’ll in finding it simple to make use of my template and do that evaluation your self.
Anything else distinctive you’re doing along with your log information that I haven’t discussed? Tweet me.
#search engine marketing #Log #Document #Research #Template #Integrated




