
On August 1st, 2018 an set of rules replace took 50% of visitors from a consumer web site within the automobile vertical. An research of the replace made me positive that the most productive plan of action used to be … to do not anything. So what came about?
Certain sufficient, on October fifth, that web site regained all of its visitors. Right here’s why I used to be positive doing not anything used to be the appropriate factor to do and why I disregarded any E-A-T chatter.
E-A-T My Shorts

I in finding the obsession with the Google Score Pointers to be bad for the search engine marketing group. If you happen to’re unfamiliar with this acronym it stands for Experience, Authoritativeness and Trustworthiness. It’s central to the printed Google Score Pointers.
The issue is the ones pointers and E-A-T are now not set of rules alerts. Don’t imagine me? Imagine Ben Gomes, long-time seek high quality engineer and new head of seek at Google.
“You’ll view the rater pointers as the place we wish the quest set of rules to move,” Ben Gomes, Google’s vice chairman of seek, assistant and information, instructed CNBC. “They don’t inform you how the set of rules is score effects, however they basically display what the set of rules will have to do.”
So I’m induced once I listen anyone say they “became up the load of experience” in a up to date set of rules replace. Although the basis had been true, it’s important to attach that to how the set of rules would replicate that fluctuate. How would Google make adjustments algorithmically to replicate upper experience?
Google doesn’t have 3 giant knobs in a depressing administrative center secure through biometric scanners that lets them alternate E-A-T at will.
Monitoring Google Scores
Earlier than I transfer on I’ll do a deeper dive into high quality rankings. I poked round to look if there are subject matter patterns to Google rankings and algorithmic adjustments. It’s lovely simple to take a look at referring visitors from the websites that carry out rankings.
![]()
The 4 websites I’ve known are raterlabs.com, raterhub.com, leapforceathome.com and appen.com. At the present there’s in reality handiest variants of appen.com, which rebranded in the previous couple of months. Both approach, create a sophisticated section and you’ll begin to see when raters have visited your web site.
And sure, those are rankings. A snappy take a look at the referral trail makes it transparent.
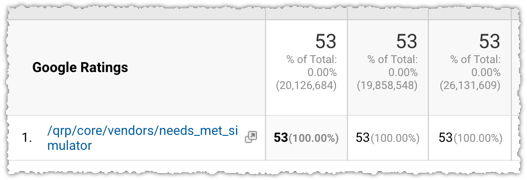
The /qrp/ stands for high quality score program and the needs_met_simulator turns out lovely self-explanatory.
It may be fascinating to then take a look at the downstream visitors for those domain names.
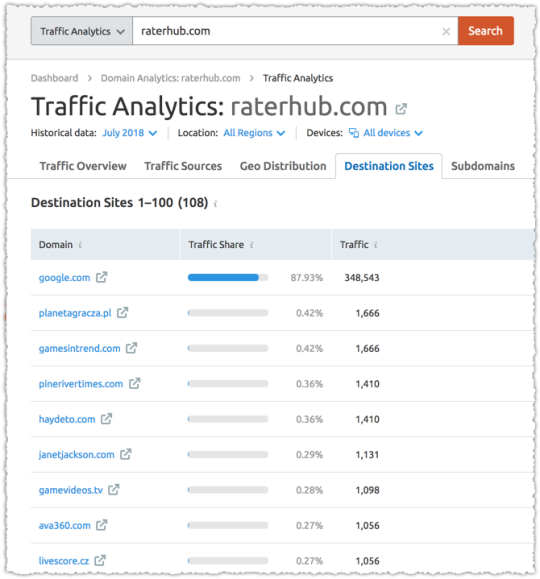
Cross the additional distance and you’ll decide what web page(s) the raters are gaining access to in your web site. Oddly, they usually appear to concentrate on one or two pages, the usage of them as a consultant for high quality.
Past that, the patterns are laborious to tease out, specifically since I’m undecided what duties are really being carried out. A far better set of this information throughout masses (most likely 1000’s) of domain names may produce some perception however for now it kind of feels so much like studying tea leaves.
Acceptance and Coaching
The standard score program has been described in some ways so I’ve at all times been hesitant to label it something or every other. Is it some way for Google to look if their contemporary set of rules adjustments had been efficient or is it some way for Google to assemble coaching knowledge to tell set of rules adjustments?
The solution appears to be sure.
Appen is the corporate that recruits high quality raters. And their pitch makes it lovely transparent that they really feel their venture is to offer coaching knowledge for system finding out by way of human interactions. Necessarily, they crowdsource categorized knowledge, which is extremely wanted in system finding out.
The query then turns into how a lot Google depends upon and makes use of this set of knowledge for his or her system finding out algorithms.
“Studying” The High quality Score Pointers

To know the way a lot Google depends upon this information, I feel it’s instructive to take a look at the tips once more. However for me it’s extra about what the tips don’t point out than what they do point out.
What question categories and verticals does Google appear to concentrate on within the score pointers and which of them are necessarily invisible? Certain, the tips may also be carried out extensively, however one has to consider why there’s a bigger focal point on … say, recipes and lyrics, proper?
Past that, do you assume Google may just depend on rankings that quilt a microscopic proportion of general queries? Significantly. Take into accounts that. The question universe is very large! Even the question magnificence universe is massive.
And Google doesn’t appear to be including assets right here. As a substitute, in 2017 they in truth reduce assets for raters. Now most likely that’s modified however … I nonetheless can’t see this being a complete method to tell the set of rules.
The raters obviously serve as as a extensive acceptance take a look at on set of rules adjustments (despite the fact that I’d bet those qualitative measures wouldn’t outweigh the quantitative measures of luck) but in addition appear to be deployed extra tactically when Google wishes explicit comments or coaching knowledge for an issue.
Maximum just lately that used to be the case with the faux information drawback. And in the beginning of the standard rater program I’m guessing they had been suffering with … lyrics and recipes.
So if we predict again to what Ben Gomes says, the way in which we will have to be studying the tips is set what spaces of focal point Google is maximum all for tackling algorithmically. As such I’m hugely extra all for what they are saying about queries with a couple of meanings and working out consumer intent.
On the finish of the day, whilst the score pointers are fascinating and supply very good context, I’m having a look in other places when inspecting set of rules adjustments.
Glance At The SERP
It surprises so much what number of SEOs infrequently without delay take a look at the SERPs, however do this handiest via “the 👀 “ of a device. Disgrace! Take a look at them & youl’ll:
1) see obviously the quest intent detected through Google
2) see the way to layout your content material
3) in finding On SERPS search engine marketing alternatives pic.twitter.com/Wr4OYAcmiG— Gianluca Fiorelli (@gfiorelli1) October 23, 2018
This Tweet through Gianluca resonated strongly with me. There’s so a lot to be discovered after an set of rules replace through in truth having a look at seek effects, specifically for those who’re monitoring visitors through question magnificence. Doing so I got here to a easy conclusion.
For the final 18 months or so maximum set of rules updates had been what I confer with as language working out updates.
This is a part of a bigger effort through Google round Herbal Language Working out (NLU), form of a subsequent era of Herbal Language Processing (NLP). Language working out updates have a profound affect on what form of content material is extra related for a given question.
For people that grasp on John Mueller’s each phrase, you’ll acknowledge that repeatedly he’ll say that it’s merely about content material being extra related. He’s proper. I simply don’t assume many are listening. They’re listening to him say that, however they’re now not being attentive to what it approach.
Neural Matching
The massive information in overdue September 2018 used to be round neural matching.
However we’ve now reached the purpose the place neural networks can assist us take a significant jump ahead from working out phrases to working out ideas. Neural embeddings, an method evolved within the box of neural networks, let us grow to be phrases to fuzzier representations of the underlying ideas, after which fit the ideas within the question with the ideas within the record. We name this method neural matching. This will permit us to deal with queries like: “why does my TV glance atypical?” to floor probably the most related effects for that query, despite the fact that the precise phrases aren’t contained within the web page. (By means of the way in which, it seems the reason being known as the cleaning soap opera impact).
Danny Sullivan went directly to confer with them as tremendous synonyms and quite a few weblog posts sought to hide this new matter. And whilst neural matching is fascinating, I feel the underlying box of neural embeddings is way more vital.
Looking at seek effects and inspecting key phrase tendencies you’ll see how the content material Google chooses to floor for positive queries adjustments through the years. Significantly people, there’s so a lot worth in having a look at how the combine of content material adjustments on a SERP.
As an example, the question ‘Toyota Camry Restore’ is a part of a question magnificence that has fractured intent. What’s it that individuals are on the lookout for once they seek this time period? Are they on the lookout for restore manuals? For restore stores? For home made content material on repairing that particular make and type?
Google doesn’t know. So it’s been biking via those other intents to look which ones plays the most productive. You get up someday and it’s restore manuals. A month of so later they necessarily disappear.
Now, clearly this isn’t finished manually. It’s now not even finished in a conventional algorithmic sense. As a substitute it’s finished via neural embeddings and system finding out.
Neural Embeddings
Let me first get started out through pronouncing that I discovered much more right here than I anticipated as I did my due diligence. Prior to now, I had finished sufficient studying and analysis to get a way of what used to be taking place to assist tell and provide an explanation for algorithmic adjustments.
And whilst I wasn’t flawed, I discovered I used to be approach at the back of on simply how a lot were happening over the previous couple of years within the realm of Herbal Language Working out.
Oddly, some of the higher puts to begin is on the finish. Very just lately, Google open-sourced one thing known as BERT.

BERT stands for Bidirectional Encoder Representations from Transformers and is a brand new method for pre-NLP coaching. Yeah, it will get dense temporarily. However the next excerpt helped put issues into point of view.
Pre-trained representations can both be context-free or contextual, and contextual representations can additional be unidirectional or bidirectional. Context-free fashions akin to word2vec or GloVe generate a unmarried phrase embedding illustration for each and every phrase within the vocabulary. As an example, the phrase “financial institution” would have the similar context-free illustration in “checking account” and “financial institution of the river.” Contextual fashions as an alternative generate a illustration of each and every phrase this is in accordance with the opposite phrases within the sentence. As an example, within the sentence “I accessed the checking account,” a unidirectional contextual type would constitute “financial institution” in accordance with “I accessed the” however now not “account.” Then again, BERT represents “financial institution” the usage of each its earlier and subsequent context — “I accessed the … account” — ranging from the very backside of a deep neural community, making it deeply bidirectional.
I used to be lovely well-versed in how word2vec labored however I struggled to know the way intent could be represented. In brief, how would Google have the ability to alternate the related content material delivered on ‘Toyota Camry Restore’ algorithmically? The solution is, in many ways, contextual phrase embedding fashions.
Vectors
None of this will make sense for those who don’t perceive vectors. I imagine many, sadly, run for the hills when the dialog turns to vectors. I’ve at all times referred to vectors as tactics to constitute phrases (or sentences or paperwork) by way of numbers and math.
I feel those two slides from a 2015 Yoav Goldberg presentation on Demystifying Neural Phrase Embeddings does a greater process of describing this dating.

So that you don’t have to totally perceive the verbiage of “sparse, prime dimensional” or the mathematics at the back of cosine distance to grok how vectors paintings and will replicate similarity.
You shall know a phrase through the corporate it assists in keeping.
That’s a well-known quote from John Rupert Firth, a outstanding linguist and the overall concept we’re getting at with vectors.
word2vec
In 2013, Google open-sourced word2vec, which used to be an actual turning level in Herbal Language Working out. I feel many within the search engine marketing group noticed this preliminary graph.
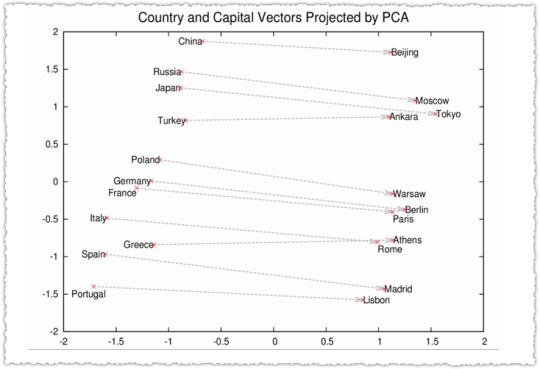
Cool proper? As well as there used to be some awe round vector mathematics the place the type may just are expecting that [King] – [Man] + [Woman] = [Queen]. It used to be a revelation of varieties that semantic and syntactic buildings had been preserved.
Or in different phrases, vector math in reality mirrored herbal language!
What I misplaced monitor of used to be how the NLU group started to unpack word2vec to raised know the way it labored and the way it could be tremendous tuned. So much has came about since 2013 and I’d be thunderstruck if a lot of it hadn’t labored its approach into seek.
Context
Those 2014 slides about Dependency Based totally Phrase Embeddings in reality drives the purpose house. I feel the entire deck is superb however I’ll cherry select to assist attach the dots and alongside the way in which take a look at to provide an explanation for some terminology.
The instance used is having a look at how you could constitute the phrase ‘discovers’. The use of a bag of phrases (BoW) context with a window of two you handiest seize the 2 phrases earlier than and after the objective phrase. The window is the choice of phrases across the goal that will probably be used to constitute the embedding.

So right here, telescope would now not be a part of the illustration. However you don’t have to make use of a easy BoW context. What for those who used every other technique to create the context or dating between phrases. As a substitute of easy words-before and words-after what for those who used syntactic dependency – one of those illustration of grammar.
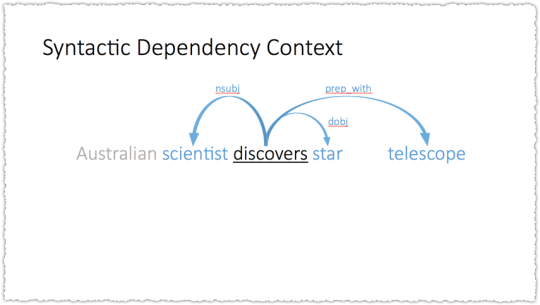
All at once telescope is a part of the embedding. So it’s worthwhile to use both means and also you’d get very other effects.

Syntactic dependency embeddings induce useful similarity. BoW embeddings induce topical similarity. Whilst this explicit case is fascinating the larger epiphany is that embeddings can alternate in accordance with how they’re generated.
Google’s working out of the that means of phrases can alternate.
Context is a method, the scale of the window is every other, the kind of textual content you employ to coach it or the quantity of textual content it’s the usage of are all ways in which may affect the embeddings. And I’m positive there are different ways in which I’m now not bringing up right here.
Past Phrases
Phrases are construction blocks for sentences. Sentences construction blocks for paragraphs. Paragraphs construction blocks for paperwork.
Sentence vectors are a sizzling matter as you’ll see from Skip Concept Vectors in 2015 to An Environment friendly Framework for Studying Sentence Representations, Common Sentence Encoder and Studying Semantic Textual Similarity from Conversations in 2018.
Google (Tomas Mikolov particularly earlier than he headed over to Fb) has additionally finished analysis in paragraph vectors. As you could be expecting, paragraph vectors are in some ways a mix of phrase vectors.
In our Paragraph Vector framework (see Determine 2), each paragraph is mapped to a singular vector, represented through a column in matrix D and each phrase may be mapped to a singular vector, represented through a column in matrix W. The paragraph vector and phrase vectors are averaged or concatenated to are expecting the following phrase in a context. Within the experiments, we use concatenation because the technique to mix the vectors.
The paragraph token may also be regarded as every other phrase. It acts as a reminiscence that recollects what’s lacking from the present context – or the subject of the paragraph. Because of this, we frequently name this type the Disbursed Reminiscence Fashion of Paragraph Vectors (PV-DM).
The data that you’ll create vectors to constitute sentences, paragraphs and paperwork is vital. However it’s extra vital for those who consider the prior instance of ways the ones embeddings can alternate. If the phrase vectors alternate then the paragraph vectors would alternate as nicely.
And that’s now not even making an allowance for the other ways you could create vectors for variable-length textual content (aka sentences, paragraphs and paperwork).
Neural embeddings will alternate relevance it doesn’t matter what degree Google is the usage of to grasp paperwork.
Questions

Chances are you’ll surprise why there’s the sort of flurry of labor on sentences. Factor is, lots of the ones sentences are questions. And the quantity of analysis round query and answering is at an all-time prime.
That is, partly, since the knowledge units round Q&A are tough. In different phrases, it’s in reality simple to coach and evaluation fashions. However it’s additionally obviously as a result of Google sees the way forward for seek in conversational seek platforms akin to voice and assistant seek.
Excluding the analysis, or the expanding incidence of featured snippets, simply take a look at the identify Ben Gomes holds: vice chairman of seek, assistant and information. Seek and assistant are being controlled through the identical person.
Working out Google’s construction and present priorities will have to assist long term evidence your search engine marketing efforts.
Relevance Matching and Score
Clearly you’re questioning if any of that is in truth appearing up in seek. Now, even with out discovering analysis that helps this concept, I feel the solution is apparent given the period of time since word2vec used to be launched (5 years), the focal point in this space of analysis (Google Mind has a space of focal point on NLU) and advances in era to fortify and productize this kind of paintings (TensorFlow, Transformer and TPUs).
However there is a number of analysis that presentations how this paintings is being built-in into seek. Possibly the perfect is one others have discussed in the case of Neural Matching.

The highlighted section makes it transparent that this type for matching queries and paperwork strikes past context-insensitive encodings to wealthy context-sensitive encodings. (Take into account that BERT depends upon context-sensitive encodings.)
Assume for a second about how the matching type may alternate for those who swapped the BoW context for the Syntactic Dependency context within the instance above.
Frankly, there’s a ton of analysis round relevance matching that I want to make amends for. However my head is beginning to harm and it’s time to convey this backtrack from the theoretical to the observable.
Syntax Adjustments
I become on this matter once I noticed positive patterns emerge all through set of rules adjustments. A shopper may see a decline in a web page sort however inside of that web page sort some higher whilst others lowered.
The disparity there by myself used to be sufficient to make me take a nearer glance. And once I did I realized that lots of the ones pages that noticed a decline didn’t see a decline in all key phrases for that web page.
As a substitute, I discovered {that a} web page may lose visitors for one question word however then acquire again a part of that visitors on an overly identical question word. The adaptation between the 2 queries used to be infrequently small however obviously sufficient that Google’s relevance matching had modified.
Pages ranked for one form of syntax and now not every other.
Right here’s some of the examples that sparked my hobby in August of 2017.
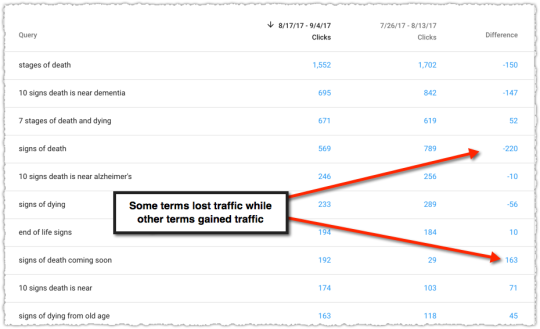
This web page noticed each losers and winners from a question point of view. We’re now not speaking small disparities both. They misplaced so much on some however noticed a big acquire in others. I used to be specifically within the queries the place they received visitors.
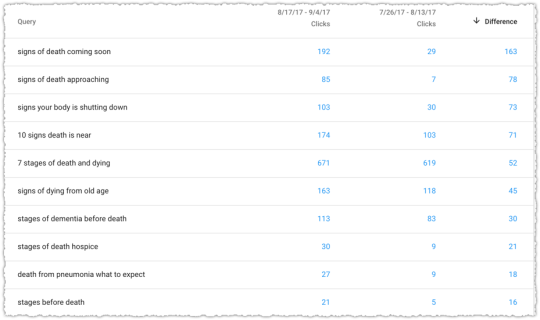
The queries with the largest proportion positive factors had been with modifiers of ‘coming quickly’ and ‘coming near’. I regarded as the ones synonyms of varieties and got here to the belief that this web page (record) used to be now higher matching for some of these queries. Even the positive factors in phrases with the phrase ‘earlier than’ may fit the ones different modifiers from a unfastened syntactic point of view.
Did Google alternate the context in their embeddings? Or alternate the window? I’m now not positive nevertheless it’s transparent that the web page continues to be related to a constellation of topical queries however that some are extra related and a few much less in accordance with Google’s working out of language.
Most up-to-date set of rules updates appear to be adjustments within the embeddings used to tell the relevance matching algorithms.
Language Working out Updates
If you happen to imagine that Google is rolling out language working out updates then the velocity of set of rules adjustments makes extra sense. As I discussed above there might be a lot of ways in which Google tweaks the embeddings or the relevance matching set of rules itself.
Now not handiest that however all of that is being finished with system finding out. The replace is rolled out after which there’s a dimension of luck in accordance with time to lengthy click on or how temporarily a seek outcome satisfies intent. The comments or reinforcement finding out is helping Google perceive if that replace used to be certain or unfavorable.
One in every of my contemporary obscure Tweets used to be about this statement.
Attention-grabbing how prime quantity queries start to alternate post-algorithm quicker than mid and long-tail queries. The system learns and will make a decision quicker with extra knowledge. #seo
— AJ Kohn (@ajkohn) August 13, 2018
Or the dataset that feeds an embedding pipeline may replace and the brand new coaching type is then fed into gadget. This is able to even be vertical explicit as nicely since Google may make the most of a vertical explicit embeddings.
August 1 Error
In response to that final commentary you could assume that I assumed the ‘medic replace’ used to be aptly named. However you’d be flawed. I noticed not anything in my research that led me to imagine that this replace used to be using a vertical explicit embedding for well being.
The very first thing I do after an replace is take a look at the SERPs. What modified? What’s now score that wasn’t earlier than? That is the primary approach I will begin to select up the ‘odor’ of the alternate.
There are occasions whilst you take a look at the newly ranked pages and, whilst you would possibly not adore it, you’ll perceive why they’re score. That can suck on your shopper however I you ought to be function. However there are occasions you glance and the effects simply glance unhealthy.

The brand new content material score didn’t fit the intent of the queries.
I had 3 purchasers who had been impacted through the alternate and I merely didn’t see how the newly ranked pages would successfully translate into higher time to lengthy click on metrics. By means of my mind-set, one thing had long gone flawed all through this language replace.
So I wasn’t all in favour of working round making adjustments for no just right reason why. I’m now not going to optimize for a misheard lyric. I figured the system would ultimately be told that this language replace used to be sub-optimal.
It took longer than I’d have preferred however positive sufficient on October fifth issues reverted again to commonplace.
August 1 Updates

Then again, there have been two issues integrated within the August 1 replace that didn’t revert. The primary used to be the YouTube carousel. I’d name it the Video carousel nevertheless it’s overwhelmingly YouTube so shall we simply name a spade a spade.
Google turns out to assume that the intent of many queries may also be met through video content material. To me, that is an over-reach. I feel the theory at the back of this unit is the outdated “you’ve were given chocolate in my peanut butter” philosophy however as an alternative it’s extra like chocolate in mustard. When other people need video content material they … move seek on YouTube.
The YouTube carousel continues to be provide however its footprint is diminishing. That stated, it’ll suck a large number of clicks clear of a SERP.
The opposite alternate used to be way more vital and continues to be related nowadays. Google selected to compare query queries with paperwork that matched extra exactly. In different phrases, longer paperwork receiving questions misplaced out to shorter paperwork that matched that question.
This didn’t come as a wonder to me for the reason that consumer revel in is abysmal for questions matching lengthy paperwork. If the solution on your query is within the eighth paragraph of a work of content material you’re going to be in reality annoyed. Google isn’t going to anchor you to that segment of the content material. As a substitute you’ll must scroll and seek for it.
Enjoying disguise and move search for your solution received’t fulfill intent.
This would definitely display up in engagement and time to lengthy click on metrics. Then again, my bet is this used to be a bigger refinement the place paperwork that matched nicely for a question the place there have been a couple of vector fits had been scored not up to the ones the place there have been fewer fits. Necessarily, content material that used to be extra centered would rating higher.
Am I proper? I’m now not positive. Both approach, it’s vital to consider how this stuff could be completed algorithmically. Extra vital on this example is the way you optimize in accordance with this information.
Do You Even Optimize?
So what do you do for those who start to embody this new global of language working out updates? How are you able to, as an search engine marketing, react to those adjustments?
Site visitors and Syntax Research
The very first thing you’ll do is analyze updates extra rationally. Time is a valuable useful resource so spend it having a look on the syntax of phrases that received and misplaced visitors.
Sadly, lots of the adjustments occur on queries with a couple of phrases. This may make sense since working out and matching the ones long-tail queries would alternate extra in accordance with the working out of language. On account of this, lots of the updates lead to subject matter ‘hidden’ visitors adjustments.
All the ones queries that Google hides as a result of they’re for my part identifiable are ripe for alternate.
That’s why I spent such a lot time investigating hidden visitors. With that metric, I may just higher see when a web site or web page had taken a success on long-tail queries. From time to time it’s worthwhile to make predictions on what form of long-tail queries had been misplaced in accordance with the losses observed in visual queries. Different occasions, now not such a lot.
Both approach, you will have to be having a look on the SERPs, monitoring adjustments to key phrase syntax, checking on hidden visitors and doing so in the course of the lens of question categories if in any respect imaginable.
Content material Optimization
This put up is rather lengthy and Justin Briggs has already finished an ideal process of describing the way to do this kind of optimization in his On-page search engine marketing for NLP put up. The way you write is in reality, in reality vital.
My philosophy of search engine marketing has at all times been to make it as simple as imaginable for Google to grasp content material. A large number of this is technical nevertheless it’s additionally about how content material is written, formatted and structured. Sloppy writing will result in sloppy embedding fits.
Take a look at how your content material is written and tighten it up. Make it more straightforward for Google (and your customers) to grasp.
Intent Optimization
Normally you’ll take a look at a SERP and start to classify each and every outcome relating to what intent it could meet or what form of content material is being offered. From time to time it’s as simple as informational as opposed to industrial. Different occasions there are various kinds of informational content material.
Sure question modifiers might fit a particular intent. In its most straightforward shape, a question with ‘easiest’ most probably calls for a listing layout with a couple of choices. However it is also the information that the combo of content material on a SERP modified, which might level to adjustments in what intent Google felt used to be extra related for that question.
If you happen to practice the arc of this tale, that form of alternate is imaginable if one thing like BERT is used with context touchy embeddings which are receiving reinforcement finding out from SERPs.
I’d additionally glance to look for those who’re aggregating intent. Fulfill lively and passive intent and also you’re much more likely to win. On the finish of the day it’s so simple as ‘goal the key phrase, optimize the intent’. More uncomplicated stated than finished I do know. However that’s why some rank nicely and others don’t.
This may be the time to make use of the rater pointers (see I’m now not pronouncing you write them off totally) to remember to’re assembly the expectancies of what ‘just right content material’ looks as if. In case your primary content material is buried beneath an entire bunch of cruft you’ll have an issue.
A lot of what I see within the rater pointers is set shooting consideration as temporarily as imaginable and, as soon as captured, optimizing that spotlight. You need to reflect what the consumer looked for so that they immediately know they were given to the appropriate position. Then it’s important to persuade them that it’s the ‘proper’ solution to their question.
Engagement Optimization
How are you aware for those who’re optimizing intent? That’s in reality the $25,000 query. It’s now not sufficient to assume you’re pleasurable intent. You want some method to measure that.
Conversion fee may also be one proxy? So can also leap fee to a point. However there are many one web page periods that fulfill intent. The leap fee on a web site like StackOverflow is tremendous prime. However that’s as a result of the character of the queries and the exactness of the content material. I nonetheless assume measuring adjusted leap fee over a protracted time frame may also be an enchanting knowledge level.
I’m way more all for consumer interactions. Did they scroll? Did they unravel the web page? Did they have interaction with one thing at the web page? Those can all be monitoring in Google Analytics as occasions and the whole choice of interactions can then be measured through the years.
I love this in concept nevertheless it’s a lot tougher to do in follow. First, each and every web site goes to have various kinds of interactions so it’s by no means an out of the field form of answer. 2nd, infrequently having extra interactions is an indication of unhealthy consumer revel in. Thoughts you, if interactions are up and so too is conversion you then’re most definitely ok.
But, now not everybody has a blank conversion mechanism to validate interplay adjustments. So it comes right down to interpretation. I for my part love this a part of the process because it’s about getting to grasp the consumer and defining a psychological type. However only a few organizations embody knowledge that may’t be validated with a p-score.
Those that are prepared to optimize engagement will inherit the SERP.
There are simply too many examples the place engagement is obviously a consider score. Whether or not or not it’s a web site score for a aggressive question with simply 14 phrases or a root time period the place low engagement has produced a SERP geared for a extremely attractive modifier time period as an alternative.
The ones certain through fears round ‘skinny content material’ because it pertains to phrase depend are lacking out, specifically in the case of Q&A.
TL;DR
Contemporary Google set of rules updates are adjustments to their working out of language. As a substitute of specializing in E-A-T, which aren’t algorithmic elements, I beg you to take a look at the SERPs and analyze your visitors together with the syntax of the queries.
The Subsequent Submit: What I Realized In 2018
The Earlier Submit: Monitoring Hidden Lengthy-Tail Seek Site visitors
#Set of rules #Research #Age #Embeddings




